搜索到
4
篇与
的结果
-
 四剑客 @TOC四剑客特点擅长find找出文件查找文件,目录,find与其他命令配合grep、egrep过滤过滤速度快,检查正则,加上颜色sed过滤过滤,替换(反向引用),取行,修改文件内容awk过滤过滤,取行,取列,统计与计算1.find:star::star::star::star::star:1.1.概述1.2.find命令的基本用法:star::star::star::star::star:find常用选项 -type类型f文件 d目录-name指定文件名,默认精确匹配,加上*模糊-size指定大小 +10M 大于10M -100k 小于100kcurl cht.sh/find1.2.1.找出/etc/目录下面以.conf结尾的文件find /etc/ -type f -name '*.conf' find 目录 类型 名字 find /etc/ -type f -name 'host*' #以host开头 找出/bin/ /sbin/ 文件中包含ip的文件 find /bin/ /sbin/ -type f -name '*ip*'1.2.2.找出/etc/目录下面以.conf结尾的文件大于小于10kfind /etc/ -type f -name '*.conf' -size +10k # 大于+ # 小于- # 大于小于无符号1.2.3.找出/var/log下面以.log结尾的文件并且修改时间大于3天找出系统中比较旧的日志,文件。 根据时间查找 #3天之前 find /var/log/ -type f -name '*.log' -mtime +3 #最近3天 find /var/log/ -type f -name '*.log' -mtime -31.2.4.查找文件或目录的时候不区分大小写find /etc/ -type f -iname '*.conf'1.3.find与其他命令配合:star::star::star::star::star:1.3.1.find找出文件后进行删除类似的命令还有,查看,过滤,替换....创建测试环境mkdir -p /app/logs touch /app/logs/access{01..10}.logfind /app/logs/ -type f -name '*.log'方法01:find与反引号:star::star::star::star::star:rm -f `find /app/logs/ -type f -name '*.log'`方法02:find 管道:star::star::star::star::star:find /app/logs -type f -name '*.log' | xargs rm -f|与|xargs 区别|传递的是字符串,文字符号|xargs 传递的是参数 命令后面文件,目录方法03:find选项 -exec:star::star::star::star::star:find /app/logs -type f -name '*.log' -exec 命令 \;结束符号 find /app/logs -type f -name '*.log' -exec rm -f {} \; -exec 命令 {} \; {}前面find找出的文件内容 \;结尾标记.1.3.2.找出/etc/下以.conf结尾的文件与打包压缩/backup/方法01:find+反引号tar czf /backup/etc-conf.tar.gz `find /etc/ -type f -name '*.conf'`方法02:find | xargsfind /etc/ -type f -name '*.conf' | xargs tar czf /backup/etc-conf.tar.gz方法03:find -exec :warning::warning::warning:find /etc/ -type f -name '*.conf' -exec tar czf /backup/etc-conf.tar.gz {} \; 有坑,发现打包压缩后只有1个文件 tar tf /backup/etc-conf.tar.gz find 与 -exec执行流程 find找出1个文件,exec执行1次 find /etc/ -type f -name '*.conf' -exec tar czf /backup/etc-conf.tar.gz {} + + 先执行前面命令执行完成,结果一次性性通过exec传递给后面的命令1.3.3.find命令与cp/mv开启yum缓存 vim /etc/yum.conf keepcache=1 #开启缓存软件包功能 缓存/var/cache/yum目录 以.rpm结尾 需求: 把/var/cache/yum 目录 以.rpm结尾,复制/移动01:find+反引号cp `find /var/cache/yum/ -type f -name '*.rpm'` /backup/rpms/02:find + | xargsfind /var/cache/yum/ -type f -name '*.rpm' | xargs cp -t /backup/rpms/find与| xargs传参cp /backup/rpms/ 参数 ... . .. . . .cp 文件 目录 目录(目标)cp -t 目录(目标) 文件 目录cp /etc/hosts /etc/hostname /tmp/ \cp -t /tmp/ /etc/hosts /etc/hostname03:find + execfind /var/cache/yum/ -type f -name '*.rpm' -exec cp {} /backup/rpms/ \;1.4.小结:white_check_mark: find目录根据指定目录,文件类型,文件名,大小,时间查找文件/目录:white_check_mark: find与一些命令搭配(rm,ls,查看命令,sed):white_check_mark: find与打包压缩:white_check_mark: find与cp/mv2.sed:star::star::star::star::star:2.1.目标:white_check_mark: sed增删改查:white_check_mark: sed查找(类似于grep过滤):指定行号,过滤范围:white_check_mark: sed替换功能:white_check_mark: sed删除功能:white_check_mark: sed增加功能(>>):white_check_mark: 脚本中sed与变量2.2.sed命令查找:star::star::star::star::star:sed命令格式选项“找谁干啥”参数sed-n'3p'/etc/passwd-n 取消默认输出一般与p指令一起使用 -r sed命令支持扩展正则 -i 修改文件内容 -i.bak 先备份后修改 找谁:条件,指定行,范围 干啥:增删改查 2.2.1.根据行号进行过滤sed -n '3p' /etc/passwd 打印第三行 -n 取消sed命令的默认输出 p输出print2.2.2.根据行号范围进行过滤# 从第3行开始到第9行结束 sed -n '3,9p' /etc/passwd # 从第10行到最后一行 sed -n '10,$p' /etc/passwd # 文件最后一行 sed -n '$p' /etc/passwd2.2.3.类似于grep/egrep进行过滤# 过滤指定内容 // sed -n '/root/p' /etc/passwd # 使用正则 记得加上-r sed -nr '/root|dange/p' /etc/passwd2.2.4.取出文件中某个范围的内容seq 3 25 >num.txt # 从包含5的行到包含15的行 sed -n '/5/,/15/p' num.txt # 精确匹配 sed -n '/^5/,/^15/p' num.txt2.2.5.日志处理案例access.log过滤出 11点00分到11:10分结束的标志温馨提示::a: 先去检查下过滤是否精确:b: 检查是否有对应时间点的日志(开始时间,结束时间)是否精确只用11:00 可能会匹配到11:00:00还有可能是11分00秒 11:00:00 多些一点点就行是否存在的问题grep '11:00:00' access.log | wc -l # 不存在 grep '11:10:00' access.log | wc -l # 存在多个最后修改为11:02:00 到 11::10:00 范围的日志sed -n '/11:02:00/,/11:10:00/p' access.log | wc -l sed -n '/11:02:00/,/11:10:00/p' access.log >1102-1110.log日志处理案例secure过滤出11点00分开始到11:10分结束的日志grep '11:00:00' secure-20161219 grep '11:10:00' secure-20161219 # 过滤出日志 sed -n '/16 11:00:00/,/16 11:10:00/p' secure-20161219 # 统计数量 sed -n '/16 11:00:00/,/16 11:10:00/p' secure-20161219 | wc -l # 统计失败的次数 sed -n '/16 11:00:00/,/16 11:10:00/p' secure-20161219|grep -i 'faild password'|wc -l2.2.5.小结查找功能根据行号类似于grep/egrep:进行过滤 //范围的过滤:/从哪里来/,/到哪里去/ 日志过滤2.3.sed改(替换):star::star::star::star::star:2.3.1.把文件中的dange替换为libai用于修改配置文件内容's###g's sub替换 substituteg 全局替换global's###g''s@@@g''s///g'cat >sed.txt<<EOF dange dange dange libai996 12306 EOF sed 's#dange#libai#g' sed.txt sed -i 's#dange#libai#g' sed.txt修改文件之前通过sed命令进行备份,然后进行修改sed -i.bak 's#dange#libai#g' passwd先备份/etc/ssh/sshd_config到当前文件目录,然后修改# Port 22 改为 Port 52114 sed 's|#Port 22|Port 52114|g$' sshd_config # 修改之后的查看 egrep -v '^$|#' sshd_config2.3.2.复制/etc/passwd到当前目录,把passwd文件的第1列和最后一列调换位置对每一行的内容进行处理sed命令反向引用/后向引用简单例子echo 123456 | sed -r 's#(12)(34)(56)#\3\2\1#g' 563412 把目标通过()括起来分组,后面通过\数字进行引用操作# 原始位置 [root@nfs01 ~]# head -n5 passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin # 替换为 [root@nfs01 ~]# sed -r 's#^(.*)(:x.*:)(.*)#\3\2\1#g' passwd /bin/bash:x:0:0:root:/root:root /sbin/nologin:x:1:1:bin:/bin:bin /sbin/nologin:x:2:2:daemon:/sbin:daemon /sbin/nologin:x:3:4:adm:/var/adm:adm /sbin/nologin:x:4:7:lp:/var/spool/lpd:lp # 替换为 [root@nfs01 ~]# sed -r 's#^(.*)(:x.*:.*/)(.*)#\3\2\1#g' passwd bash:x:0:0:root:/root:/bin/root nologin:x:1:1:bin:/bin:/sbin/bin nologin:x:2:2:daemon:/sbin:/sbin/daemon nologin:x:3:4:adm:/var/adm:/sbin/adm nologin:x:4:7:lp:/var/spool/lpd:/sbin/lp2.3.3.sed替换小结sed替换格式,选项-i.bak's###g'sed对数据进行精加工:第1列,最后1列2.4.sed删除:star::star::star::star::star:按照行d===delete#删除第3行 seq 10 | sed '3d' #删除以1开头的行 seq 10 | sed '/^1/d'2.5.sed增加:star::star::star::star::star:cai 菜 clean append inserta append在指定行下面增加1行i insert在指定行上面增加1行c replace/clean 清空指定行,然后写入内容# a append在指定行后面追加一行 [root@nfs01 ~]# seq 10 | sed '3a dange' 1 2 3 dange 4 5 6 7 8 9 10 # i insert在指定行上面增加1行 [root@nfs01 ~]# seq 10 | sed '3i dange' 1 2 dange 3 4 5 6 7 8 9 10 # c replace/clean 清空指定行,然后写入内容 [root@nfs01 ~]# seq 10 | sed '3c dange' 1 2 dange 4 5 6 7 8 9 102.6.sed命令与变量cat >sed.txt<<EOF dange dange dange libai996 12306 EOF src=dange dest=libai sed "s#$src#$dest#g" sed.txt[root@nfs01 ~]# src=dange [root@nfs01 ~]# dest=libai [root@nfs01 ~]# sed "s#$src#$dest#g" sed.txt libai libai libai libai996 123062.7.总结[ ] 可以根据过滤需求在基础正则和扩展正则中进行选择:==^ $ ^$ .* [] | + ()==[ ] grep/egrep过滤[ ] sed过滤,替换,删除,修改文件内容[ ] awk过滤,取列[ ] 会使用sed命令取行(行号),取行(范围)[ ] 会使用sed命令替换[ ] 会使用sed命令进行对数据加工(反向引用)[ ] sed使用变量3.awk:star::star::star::star::star:3.1.目标使用awk取行使用awk取列使用awk取行+取列通过awk进行初步计算与统计(eg,统计次数(wc -l),求和)3.2.取行类似于sed , grep,使用起来更加方便3.2.1.取出/etc/passwd第3行NR awk中的内置变量NR Number of Record 记录号,行号==2个等号表示等于# 取出第一行 awk 'NR==1' passwd # 取出大于等于第三行,小于等于第10行的区间 awk 'NR>=3 && NR<=10' passwd # 取出大于等于第三行的 awk 'NR>=3' passwd3.2.2.取出/etc/passwd 第3行到10行awk 'NR>=3' passwd == 等于 != 不等于 >= 大于等于 > 大于 <= 小于等于 < 小于 awk 'NR>=3 && NR<=10' passwd && 并且,2个条件同时成立 3.2.3.取出/etc/passwd 中包含bash的行类似于egrep/grep/sed -n '//p'awk过滤只需要使用//即可grep 'bash' passwd sed -n '/bash/p' passwd awk '/bash/' passwdawk使用正则awk '/root|dange/' passwd3.2.4.取出日志中指定时间段内的日志取出范围的日志的格式seq 5 20 | head -n '/从哪里来/ , /到哪里去/p' seq 5 20 | awk '/从哪里来/ , /到哪里去/p'取出时间范围日志过滤出11号15:00到16:00的日志 检查是否有11号的15:00的日志 grep '11 15:00' secure-20161219 | wc -l 检查是否有11号的16:00的日志 grep '11 16:00' secure-20161219 | wc -l sed -n '//,//p' secure-20161219 sed -n '/11 15:00/,/11 16:00/p' secure-20161219 | wc -l sed -n '/11 15:00/,/11 16:00/p' secure-20161219 > secure-15-16过滤access.log与注意事项过滤11:30分到11:31分日志 sed -n '/22.Nov.2015:11:30:00/,/22.Nov.2015:11:31:00/p' access.log | wc -l sed -n '/22\/Nov\/2015:11:30:00/,/22\/Nov\/2015:11:31:00/p' access.log | wc -l sed -n '/\[22\/Nov\/2015:11:30:00/,/\[22\/Nov\/2015:11:31:00/p' access.log | wc -l[root@nfs01 ~]# head -n2 access.log 101.226.61.184 - - [22/Nov/2015:11:02:00 +0800] "GET /mobile/sea-modules/gallery/zepto/1.1.3/zepto.js HTTP/1.1" 200 24662 "http://m.oldboyedu.com.cn/mobile/theme/oldboyedu/home/index.html" "Mozilla/5.0 (Linux; U; Android 5.1.1; zh-cn; HUAWEI CRR-UL00 Build/HUAWEICRR-UL00) AppleWebKit/533.1 (KHTML, like Gecko)Version/4.0 MQQBrowser/5.4 TBS/025478 Mobile Safari/533.1 MicroMessenger/6.3.7.51_rbb7fa12.660 NetType/3gnet Language/zh_CN" 101.226.61.184 - - [22/Nov/2015:11:02:00 +0800] "GET /mobile/theme/oldboyedu/common/js/baiduAnalytics.js HTTP/1.1" 200 526 "http://m.oldboyedu.com.cn/mobile/theme/oldboyedu/home/index.html" "Mozilla/5.0 (Linux; U; Android 5.1.1; zh-cn; HUAWEI CRR-UL00 Build/HUAWEICRR-UL00) AppleWebKit/533.1 (KHTML, like Gecko)Version/4.0 MQQBrowser/5.4 TBS/025478 Mobile Safari/533.1 MicroMessenger/6.3.7.51_rbb7fa12.660 NetType/3gnet Language/zh_CN" [root@nfs01 ~]# sed -n '/22.Nov.2015:11:30:00/,/22.Nov.2015:11:31:00/p' access.log | wc -l 3204 [root@nfs01 ~]# sed -n '/22\/Nov\/2015:11:30:00/,/22\/Nov\/2015:11:31:00/p' access.log | wc -l 3204 [root@nfs01 ~]# sed -n '/\[22\/Nov\/2015:11:30:00/,/\[22\/Nov\/2015:11:31:00/p' access.log | wc -l 32043.2.5.小结类似于sed命令NR内置变量用于表示行号Number of Record 记录号(行号)结合符号== != >= <= > <3.3.取列3.3.1.取出ls -l /etc/hosts 文件第3列,最后一列NF awk 内置变量NF Number of Fields 每一行有多少列,列数 $NFll /etc/hosts | awk '{print $3,$5,$(NF-1),$NF}' # 取出第5列和最后一列 ll | awk '{print $5,$NF}' # 取出列进行对齐 ll | awk '{print $5,$NF}' | column -tcolumn -t 对前面的内容进行对齐# 取出列进行对齐 [root@nfs01 ~]# ll | awk '{print $5,$NF}' | column -t 66912 59404199 access.log 9080283 access_log 3033 anaconda-ks.cfg 3595 initial-setup-ks.cfg3.3.2.取出/etc/passwd第1列第3列和最后一列awk中默认认为每一列的标记是空格,awk默认的分隔符是==空格==一些文件或命令的结果中,每一列不是以空格分割,这时候我们需要通过awk -F选项指定新的分隔符==awk -F可以指定分隔符==[root@nfs01 ~]# awk -F: '{print $1,$3,$NF}' passwd | column -t root 0 /bin/bash bin 1 /sbin/nologin daemon 2 /sbin/nologin adm 3 /sbin/nologin lp 4 /sbin/nologin3.3.3.取出ip a s eth0 中的ip地址ip a # ip addressip a s eth0 # ip address show eth0显示指定网卡的信息awk -F支持正则表达式,正则匹配到的内容将成为分隔符ip a s ens33 | awk 'NR==3' | awk -F'[ /]+' '{print $3}' ip a s ens33 | awk 'NR==3' | awk -F'inet |/24' '{print $2}' ip addr show ens33 | awk -F'[ /]+' 'NR==3{print $3}'[root@nfs01 ~]# ip addr show ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:0c:29:35:e5:0b brd ff:ff:ff:ff:ff:ff inet 10.0.0.31/24 brd 10.0.0.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::b3ec:9b3a:4067:42a/64 scope link noprefixroute valid_lft forever preferred_lft forever [root@nfs01 ~]# ip addr show ens33 | awk 'NR==3' inet 10.0.0.31/24 brd 10.0.0.255 scope global noprefixroute ens33 [root@nfs01 ~]# ip addr show ens33 | awk 'NR==3{print $2}' 10.0.0.31/24 [root@nfs01 ~]# ip addr show ens33 | awk -F'[ /]+' 'NR==3{print $3}' 10.0.0.313.3.4.显示/etc/passwd每一行的内容和行号cat -nNR表示行号print输出$0 整行,这一行的内容awk '{print NR}' passwd awk '{print NR,$0}' passwd awk 'NR>=3{print $0}' passwd[root@nfs01 ~]# awk '{print NR,$0}' passwd 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin3.3.5.uptime取出运行时间cat /proc/uptime| awk -F. '{ run_days=$1 / 86400; run_hour=($1 % 86400)/3600; run_minute=($1 % 3600)/60; run_second=$1 % 60; printf("系统已运行:%d天%d时%d分%d秒\n",run_days,run_hour,run_minute,run_second) }';系统已运行:29天18时47分34秒 系统已运行:0天1时26分56秒[root@backup ~]# uptime 11:10:05 up 1:38, 1 user, load average: 0.00, 0.00, 0.00 [root@backup ~]# uptime | awk -F'[ ,]' '{print $5}' 1:393.3.6.取列小结取列小结awk '{print $xxx}'$1 $2 .. $NF取列$(NF-1) 取倒数第2列awk -F 选项指定分隔符,分隔符相当于是菜刀,每一列的结束标记awk -F 选项支持正则3.4.取行与取列3.4.1.awk命令格式awk -F: 'NR==1{print $1,$3,$NF}' passwd awk 选项 '找谁{干啥}' passwd 找谁:条件 用于让awk定位到某一行或几行 干啥:动作 满足上面条件后(找到这行后)如何处理这一行。print取列动作部分可以省略,输出这一行的内容相当于awk 'NR==3' /passwd #显示第3行的内容awk 'NR==3{print $0}' /passwd #显示第3行的内容3.4.2.取出ip a s eth0中的ip地址ip a s eth0 | awk 'NR==3' | awk -F'[ /]+' '{print $3}'ip a s eth0 | awk -F'[ /]+' 'NR==3{print $3}'3.4.3.取出/etc/passwd的第三列UID大于等于0,小于等于900的行awk -F: '$3>=0 && $3<=900' passwd3.4.4.取出系统磁盘使用率df -h大于10%的行df -h | awk -F'[ %]+' 'NR>1 && $5>=10'[root@nfs01 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 3.3G 0 3.3G 0% /dev tmpfs 3.3G 0 3.3G 0% /dev/shm tmpfs 3.3G 9.2M 3.3G 1% /run tmpfs 3.3G 0 3.3G 0% /sys/fs/cgroup /dev/sda3 97G 4.2G 93G 5% / tmpfs 3.3G 0 3.3G 0% /tmp /dev/sda1 1014M 167M 848M 17% /boot tmpfs 666M 0 666M 0% /run/user/0 [root@nfs01 ~]# df -h | awk -F'[ %]+' 'NR>1 && $5>=10' /dev/sda1 1014M 167M 848M 17% /boot3.4.5.过滤某一列中有什么根据指定的列进行过滤:如果第3列中包含xxxx则显示这一行 sed,grep都是基于行,这一行中有或没有xxxx$xxx~// 匹配,包含$xxx!~// 匹配,不包含/etc/passwd中第3列UID包含0或1,输出这一行的第1列,第3列和最后一列条件:行 第3列包含0或1 动作:列 输出第1列,3列,最后一列 awk -F: '$3~/[01]/ {print $1,$3,$NF}' passwd/etc/passwd中第3列UID包含0或1结尾,输出这一行的第1列,第3列和最后一列awk -F: '$3~/[01]$/ {print $1,$3,$NF}' passwd ^ 某一列的开头 $ 某一列的结尾过滤出access.log中第7列以.jpg或.bmp或.png或.gif结尾的行,统计行数access.log nginx访问日志,只要访问就会有记录第1列 ip地址第7列 用户访问的页面路径第9列 状态码,访问结果正常,异常第10列 页面大小awk '$7~/\.jpg$|\.bmp$|\.gif$|\.png$/' access.log awk '$7~/\.(jpg|bmp|gif|png)$/' access.log awk '$7~/\.jpg$|\.bmp$|\.gif$|\.png$/' access.log |wc -l awk '$7~/\.(jpg|bmp|gif|png)$/' access.log |wc -l3.5.awk计算与统计3.5.1.目标记忆awk两个常用公式使用awk进行求和使用awk进行计算的百分数(一般会与结合取行取列)3.5.2.通过awk实现wc -l效果计数,统计次数未来统计次数的需求,推荐使用wc -lawk '{统计与计算} END{awk读取文件后,才会执行,一般用于输出最后的结果}' xxx i=i+1 i=666 i=i+1 ==== i++ i+1执行,结果写入到i 当前的i 执行i=i+1 之后的i 第1次运行 0 i=0+1 1 第2次运行 1 i=1+1 2 第3次运行 2 i=2+1 3 awk '{i=i+1}END{print i}' calc.txt awk '{i++}END{print i}' calc.txt[root@nfs01 ~]# cat calc.txt |column -t libai 19 wangwu 30 huzi 80 xiaozhang 30 [root@nfs01 ~]# awk '{i++}END{print i}' calc.txt 4 [root@nfs01 ~]# awk '{i=i+1}END{print i}' calc.txt 4 [root@nfs01 ~]# wc -l calc.txt 4 calc.txt[root@nfs01 ~]# awk '{i=i+$2}END{print i}' calc.txt 1593.5.3.统计seq 10结果的总和[root@nfs01 ~]# seq 10 | awk '{sum=sum+$1} END {print sum}' 55access.log是访问日志,日志的第10列,是用户访问的资源的大小,对大小求和,形式以MB或GB形式展示[root@nfs01 ~]# awk '{i=i+$10}END{print i}' access.log 2478496663 [root@nfs01 ~]# awk '{i=i+$10}END{print i/1024/1024"MB"}' access.log 2363.68MB [root@nfs01 ~]# awk '{i=i+$10}END{print i/1024/1024/1024"GB"}' access.log 2.30828GB3.5.4.统计free结果中内存空闲率END{}一般用于数据分散在不同的行,需要使用END{}[root@nfs01 ~]# free total used free shared buff/cache available Mem: 6819580 233096 6226252 9360 360232 6332088 Swap: 2097148 0 2097148 [root@nfs01 ~]# free | awk 'NR==2' Mem: 6819580 232948 6226400 9360 360232 6332236 [root@nfs01 ~]# free | awk 'NR==2{print $NF}' 6332564 [root@nfs01 ~]# free | awk 'NR==2{print $NF/$2*100}' 92.8606 [root@nfs01 ~]# free | awk 'NR==2{print $NF/$2*100"%"}' 92.8625%4.grep:star::star::star::star::star:5.endl
四剑客 @TOC四剑客特点擅长find找出文件查找文件,目录,find与其他命令配合grep、egrep过滤过滤速度快,检查正则,加上颜色sed过滤过滤,替换(反向引用),取行,修改文件内容awk过滤过滤,取行,取列,统计与计算1.find:star::star::star::star::star:1.1.概述1.2.find命令的基本用法:star::star::star::star::star:find常用选项 -type类型f文件 d目录-name指定文件名,默认精确匹配,加上*模糊-size指定大小 +10M 大于10M -100k 小于100kcurl cht.sh/find1.2.1.找出/etc/目录下面以.conf结尾的文件find /etc/ -type f -name '*.conf' find 目录 类型 名字 find /etc/ -type f -name 'host*' #以host开头 找出/bin/ /sbin/ 文件中包含ip的文件 find /bin/ /sbin/ -type f -name '*ip*'1.2.2.找出/etc/目录下面以.conf结尾的文件大于小于10kfind /etc/ -type f -name '*.conf' -size +10k # 大于+ # 小于- # 大于小于无符号1.2.3.找出/var/log下面以.log结尾的文件并且修改时间大于3天找出系统中比较旧的日志,文件。 根据时间查找 #3天之前 find /var/log/ -type f -name '*.log' -mtime +3 #最近3天 find /var/log/ -type f -name '*.log' -mtime -31.2.4.查找文件或目录的时候不区分大小写find /etc/ -type f -iname '*.conf'1.3.find与其他命令配合:star::star::star::star::star:1.3.1.find找出文件后进行删除类似的命令还有,查看,过滤,替换....创建测试环境mkdir -p /app/logs touch /app/logs/access{01..10}.logfind /app/logs/ -type f -name '*.log'方法01:find与反引号:star::star::star::star::star:rm -f `find /app/logs/ -type f -name '*.log'`方法02:find 管道:star::star::star::star::star:find /app/logs -type f -name '*.log' | xargs rm -f|与|xargs 区别|传递的是字符串,文字符号|xargs 传递的是参数 命令后面文件,目录方法03:find选项 -exec:star::star::star::star::star:find /app/logs -type f -name '*.log' -exec 命令 \;结束符号 find /app/logs -type f -name '*.log' -exec rm -f {} \; -exec 命令 {} \; {}前面find找出的文件内容 \;结尾标记.1.3.2.找出/etc/下以.conf结尾的文件与打包压缩/backup/方法01:find+反引号tar czf /backup/etc-conf.tar.gz `find /etc/ -type f -name '*.conf'`方法02:find | xargsfind /etc/ -type f -name '*.conf' | xargs tar czf /backup/etc-conf.tar.gz方法03:find -exec :warning::warning::warning:find /etc/ -type f -name '*.conf' -exec tar czf /backup/etc-conf.tar.gz {} \; 有坑,发现打包压缩后只有1个文件 tar tf /backup/etc-conf.tar.gz find 与 -exec执行流程 find找出1个文件,exec执行1次 find /etc/ -type f -name '*.conf' -exec tar czf /backup/etc-conf.tar.gz {} + + 先执行前面命令执行完成,结果一次性性通过exec传递给后面的命令1.3.3.find命令与cp/mv开启yum缓存 vim /etc/yum.conf keepcache=1 #开启缓存软件包功能 缓存/var/cache/yum目录 以.rpm结尾 需求: 把/var/cache/yum 目录 以.rpm结尾,复制/移动01:find+反引号cp `find /var/cache/yum/ -type f -name '*.rpm'` /backup/rpms/02:find + | xargsfind /var/cache/yum/ -type f -name '*.rpm' | xargs cp -t /backup/rpms/find与| xargs传参cp /backup/rpms/ 参数 ... . .. . . .cp 文件 目录 目录(目标)cp -t 目录(目标) 文件 目录cp /etc/hosts /etc/hostname /tmp/ \cp -t /tmp/ /etc/hosts /etc/hostname03:find + execfind /var/cache/yum/ -type f -name '*.rpm' -exec cp {} /backup/rpms/ \;1.4.小结:white_check_mark: find目录根据指定目录,文件类型,文件名,大小,时间查找文件/目录:white_check_mark: find与一些命令搭配(rm,ls,查看命令,sed):white_check_mark: find与打包压缩:white_check_mark: find与cp/mv2.sed:star::star::star::star::star:2.1.目标:white_check_mark: sed增删改查:white_check_mark: sed查找(类似于grep过滤):指定行号,过滤范围:white_check_mark: sed替换功能:white_check_mark: sed删除功能:white_check_mark: sed增加功能(>>):white_check_mark: 脚本中sed与变量2.2.sed命令查找:star::star::star::star::star:sed命令格式选项“找谁干啥”参数sed-n'3p'/etc/passwd-n 取消默认输出一般与p指令一起使用 -r sed命令支持扩展正则 -i 修改文件内容 -i.bak 先备份后修改 找谁:条件,指定行,范围 干啥:增删改查 2.2.1.根据行号进行过滤sed -n '3p' /etc/passwd 打印第三行 -n 取消sed命令的默认输出 p输出print2.2.2.根据行号范围进行过滤# 从第3行开始到第9行结束 sed -n '3,9p' /etc/passwd # 从第10行到最后一行 sed -n '10,$p' /etc/passwd # 文件最后一行 sed -n '$p' /etc/passwd2.2.3.类似于grep/egrep进行过滤# 过滤指定内容 // sed -n '/root/p' /etc/passwd # 使用正则 记得加上-r sed -nr '/root|dange/p' /etc/passwd2.2.4.取出文件中某个范围的内容seq 3 25 >num.txt # 从包含5的行到包含15的行 sed -n '/5/,/15/p' num.txt # 精确匹配 sed -n '/^5/,/^15/p' num.txt2.2.5.日志处理案例access.log过滤出 11点00分到11:10分结束的标志温馨提示::a: 先去检查下过滤是否精确:b: 检查是否有对应时间点的日志(开始时间,结束时间)是否精确只用11:00 可能会匹配到11:00:00还有可能是11分00秒 11:00:00 多些一点点就行是否存在的问题grep '11:00:00' access.log | wc -l # 不存在 grep '11:10:00' access.log | wc -l # 存在多个最后修改为11:02:00 到 11::10:00 范围的日志sed -n '/11:02:00/,/11:10:00/p' access.log | wc -l sed -n '/11:02:00/,/11:10:00/p' access.log >1102-1110.log日志处理案例secure过滤出11点00分开始到11:10分结束的日志grep '11:00:00' secure-20161219 grep '11:10:00' secure-20161219 # 过滤出日志 sed -n '/16 11:00:00/,/16 11:10:00/p' secure-20161219 # 统计数量 sed -n '/16 11:00:00/,/16 11:10:00/p' secure-20161219 | wc -l # 统计失败的次数 sed -n '/16 11:00:00/,/16 11:10:00/p' secure-20161219|grep -i 'faild password'|wc -l2.2.5.小结查找功能根据行号类似于grep/egrep:进行过滤 //范围的过滤:/从哪里来/,/到哪里去/ 日志过滤2.3.sed改(替换):star::star::star::star::star:2.3.1.把文件中的dange替换为libai用于修改配置文件内容's###g's sub替换 substituteg 全局替换global's###g''s@@@g''s///g'cat >sed.txt<<EOF dange dange dange libai996 12306 EOF sed 's#dange#libai#g' sed.txt sed -i 's#dange#libai#g' sed.txt修改文件之前通过sed命令进行备份,然后进行修改sed -i.bak 's#dange#libai#g' passwd先备份/etc/ssh/sshd_config到当前文件目录,然后修改# Port 22 改为 Port 52114 sed 's|#Port 22|Port 52114|g$' sshd_config # 修改之后的查看 egrep -v '^$|#' sshd_config2.3.2.复制/etc/passwd到当前目录,把passwd文件的第1列和最后一列调换位置对每一行的内容进行处理sed命令反向引用/后向引用简单例子echo 123456 | sed -r 's#(12)(34)(56)#\3\2\1#g' 563412 把目标通过()括起来分组,后面通过\数字进行引用操作# 原始位置 [root@nfs01 ~]# head -n5 passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin # 替换为 [root@nfs01 ~]# sed -r 's#^(.*)(:x.*:)(.*)#\3\2\1#g' passwd /bin/bash:x:0:0:root:/root:root /sbin/nologin:x:1:1:bin:/bin:bin /sbin/nologin:x:2:2:daemon:/sbin:daemon /sbin/nologin:x:3:4:adm:/var/adm:adm /sbin/nologin:x:4:7:lp:/var/spool/lpd:lp # 替换为 [root@nfs01 ~]# sed -r 's#^(.*)(:x.*:.*/)(.*)#\3\2\1#g' passwd bash:x:0:0:root:/root:/bin/root nologin:x:1:1:bin:/bin:/sbin/bin nologin:x:2:2:daemon:/sbin:/sbin/daemon nologin:x:3:4:adm:/var/adm:/sbin/adm nologin:x:4:7:lp:/var/spool/lpd:/sbin/lp2.3.3.sed替换小结sed替换格式,选项-i.bak's###g'sed对数据进行精加工:第1列,最后1列2.4.sed删除:star::star::star::star::star:按照行d===delete#删除第3行 seq 10 | sed '3d' #删除以1开头的行 seq 10 | sed '/^1/d'2.5.sed增加:star::star::star::star::star:cai 菜 clean append inserta append在指定行下面增加1行i insert在指定行上面增加1行c replace/clean 清空指定行,然后写入内容# a append在指定行后面追加一行 [root@nfs01 ~]# seq 10 | sed '3a dange' 1 2 3 dange 4 5 6 7 8 9 10 # i insert在指定行上面增加1行 [root@nfs01 ~]# seq 10 | sed '3i dange' 1 2 dange 3 4 5 6 7 8 9 10 # c replace/clean 清空指定行,然后写入内容 [root@nfs01 ~]# seq 10 | sed '3c dange' 1 2 dange 4 5 6 7 8 9 102.6.sed命令与变量cat >sed.txt<<EOF dange dange dange libai996 12306 EOF src=dange dest=libai sed "s#$src#$dest#g" sed.txt[root@nfs01 ~]# src=dange [root@nfs01 ~]# dest=libai [root@nfs01 ~]# sed "s#$src#$dest#g" sed.txt libai libai libai libai996 123062.7.总结[ ] 可以根据过滤需求在基础正则和扩展正则中进行选择:==^ $ ^$ .* [] | + ()==[ ] grep/egrep过滤[ ] sed过滤,替换,删除,修改文件内容[ ] awk过滤,取列[ ] 会使用sed命令取行(行号),取行(范围)[ ] 会使用sed命令替换[ ] 会使用sed命令进行对数据加工(反向引用)[ ] sed使用变量3.awk:star::star::star::star::star:3.1.目标使用awk取行使用awk取列使用awk取行+取列通过awk进行初步计算与统计(eg,统计次数(wc -l),求和)3.2.取行类似于sed , grep,使用起来更加方便3.2.1.取出/etc/passwd第3行NR awk中的内置变量NR Number of Record 记录号,行号==2个等号表示等于# 取出第一行 awk 'NR==1' passwd # 取出大于等于第三行,小于等于第10行的区间 awk 'NR>=3 && NR<=10' passwd # 取出大于等于第三行的 awk 'NR>=3' passwd3.2.2.取出/etc/passwd 第3行到10行awk 'NR>=3' passwd == 等于 != 不等于 >= 大于等于 > 大于 <= 小于等于 < 小于 awk 'NR>=3 && NR<=10' passwd && 并且,2个条件同时成立 3.2.3.取出/etc/passwd 中包含bash的行类似于egrep/grep/sed -n '//p'awk过滤只需要使用//即可grep 'bash' passwd sed -n '/bash/p' passwd awk '/bash/' passwdawk使用正则awk '/root|dange/' passwd3.2.4.取出日志中指定时间段内的日志取出范围的日志的格式seq 5 20 | head -n '/从哪里来/ , /到哪里去/p' seq 5 20 | awk '/从哪里来/ , /到哪里去/p'取出时间范围日志过滤出11号15:00到16:00的日志 检查是否有11号的15:00的日志 grep '11 15:00' secure-20161219 | wc -l 检查是否有11号的16:00的日志 grep '11 16:00' secure-20161219 | wc -l sed -n '//,//p' secure-20161219 sed -n '/11 15:00/,/11 16:00/p' secure-20161219 | wc -l sed -n '/11 15:00/,/11 16:00/p' secure-20161219 > secure-15-16过滤access.log与注意事项过滤11:30分到11:31分日志 sed -n '/22.Nov.2015:11:30:00/,/22.Nov.2015:11:31:00/p' access.log | wc -l sed -n '/22\/Nov\/2015:11:30:00/,/22\/Nov\/2015:11:31:00/p' access.log | wc -l sed -n '/\[22\/Nov\/2015:11:30:00/,/\[22\/Nov\/2015:11:31:00/p' access.log | wc -l[root@nfs01 ~]# head -n2 access.log 101.226.61.184 - - [22/Nov/2015:11:02:00 +0800] "GET /mobile/sea-modules/gallery/zepto/1.1.3/zepto.js HTTP/1.1" 200 24662 "http://m.oldboyedu.com.cn/mobile/theme/oldboyedu/home/index.html" "Mozilla/5.0 (Linux; U; Android 5.1.1; zh-cn; HUAWEI CRR-UL00 Build/HUAWEICRR-UL00) AppleWebKit/533.1 (KHTML, like Gecko)Version/4.0 MQQBrowser/5.4 TBS/025478 Mobile Safari/533.1 MicroMessenger/6.3.7.51_rbb7fa12.660 NetType/3gnet Language/zh_CN" 101.226.61.184 - - [22/Nov/2015:11:02:00 +0800] "GET /mobile/theme/oldboyedu/common/js/baiduAnalytics.js HTTP/1.1" 200 526 "http://m.oldboyedu.com.cn/mobile/theme/oldboyedu/home/index.html" "Mozilla/5.0 (Linux; U; Android 5.1.1; zh-cn; HUAWEI CRR-UL00 Build/HUAWEICRR-UL00) AppleWebKit/533.1 (KHTML, like Gecko)Version/4.0 MQQBrowser/5.4 TBS/025478 Mobile Safari/533.1 MicroMessenger/6.3.7.51_rbb7fa12.660 NetType/3gnet Language/zh_CN" [root@nfs01 ~]# sed -n '/22.Nov.2015:11:30:00/,/22.Nov.2015:11:31:00/p' access.log | wc -l 3204 [root@nfs01 ~]# sed -n '/22\/Nov\/2015:11:30:00/,/22\/Nov\/2015:11:31:00/p' access.log | wc -l 3204 [root@nfs01 ~]# sed -n '/\[22\/Nov\/2015:11:30:00/,/\[22\/Nov\/2015:11:31:00/p' access.log | wc -l 32043.2.5.小结类似于sed命令NR内置变量用于表示行号Number of Record 记录号(行号)结合符号== != >= <= > <3.3.取列3.3.1.取出ls -l /etc/hosts 文件第3列,最后一列NF awk 内置变量NF Number of Fields 每一行有多少列,列数 $NFll /etc/hosts | awk '{print $3,$5,$(NF-1),$NF}' # 取出第5列和最后一列 ll | awk '{print $5,$NF}' # 取出列进行对齐 ll | awk '{print $5,$NF}' | column -tcolumn -t 对前面的内容进行对齐# 取出列进行对齐 [root@nfs01 ~]# ll | awk '{print $5,$NF}' | column -t 66912 59404199 access.log 9080283 access_log 3033 anaconda-ks.cfg 3595 initial-setup-ks.cfg3.3.2.取出/etc/passwd第1列第3列和最后一列awk中默认认为每一列的标记是空格,awk默认的分隔符是==空格==一些文件或命令的结果中,每一列不是以空格分割,这时候我们需要通过awk -F选项指定新的分隔符==awk -F可以指定分隔符==[root@nfs01 ~]# awk -F: '{print $1,$3,$NF}' passwd | column -t root 0 /bin/bash bin 1 /sbin/nologin daemon 2 /sbin/nologin adm 3 /sbin/nologin lp 4 /sbin/nologin3.3.3.取出ip a s eth0 中的ip地址ip a # ip addressip a s eth0 # ip address show eth0显示指定网卡的信息awk -F支持正则表达式,正则匹配到的内容将成为分隔符ip a s ens33 | awk 'NR==3' | awk -F'[ /]+' '{print $3}' ip a s ens33 | awk 'NR==3' | awk -F'inet |/24' '{print $2}' ip addr show ens33 | awk -F'[ /]+' 'NR==3{print $3}'[root@nfs01 ~]# ip addr show ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:0c:29:35:e5:0b brd ff:ff:ff:ff:ff:ff inet 10.0.0.31/24 brd 10.0.0.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::b3ec:9b3a:4067:42a/64 scope link noprefixroute valid_lft forever preferred_lft forever [root@nfs01 ~]# ip addr show ens33 | awk 'NR==3' inet 10.0.0.31/24 brd 10.0.0.255 scope global noprefixroute ens33 [root@nfs01 ~]# ip addr show ens33 | awk 'NR==3{print $2}' 10.0.0.31/24 [root@nfs01 ~]# ip addr show ens33 | awk -F'[ /]+' 'NR==3{print $3}' 10.0.0.313.3.4.显示/etc/passwd每一行的内容和行号cat -nNR表示行号print输出$0 整行,这一行的内容awk '{print NR}' passwd awk '{print NR,$0}' passwd awk 'NR>=3{print $0}' passwd[root@nfs01 ~]# awk '{print NR,$0}' passwd 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin3.3.5.uptime取出运行时间cat /proc/uptime| awk -F. '{ run_days=$1 / 86400; run_hour=($1 % 86400)/3600; run_minute=($1 % 3600)/60; run_second=$1 % 60; printf("系统已运行:%d天%d时%d分%d秒\n",run_days,run_hour,run_minute,run_second) }';系统已运行:29天18时47分34秒 系统已运行:0天1时26分56秒[root@backup ~]# uptime 11:10:05 up 1:38, 1 user, load average: 0.00, 0.00, 0.00 [root@backup ~]# uptime | awk -F'[ ,]' '{print $5}' 1:393.3.6.取列小结取列小结awk '{print $xxx}'$1 $2 .. $NF取列$(NF-1) 取倒数第2列awk -F 选项指定分隔符,分隔符相当于是菜刀,每一列的结束标记awk -F 选项支持正则3.4.取行与取列3.4.1.awk命令格式awk -F: 'NR==1{print $1,$3,$NF}' passwd awk 选项 '找谁{干啥}' passwd 找谁:条件 用于让awk定位到某一行或几行 干啥:动作 满足上面条件后(找到这行后)如何处理这一行。print取列动作部分可以省略,输出这一行的内容相当于awk 'NR==3' /passwd #显示第3行的内容awk 'NR==3{print $0}' /passwd #显示第3行的内容3.4.2.取出ip a s eth0中的ip地址ip a s eth0 | awk 'NR==3' | awk -F'[ /]+' '{print $3}'ip a s eth0 | awk -F'[ /]+' 'NR==3{print $3}'3.4.3.取出/etc/passwd的第三列UID大于等于0,小于等于900的行awk -F: '$3>=0 && $3<=900' passwd3.4.4.取出系统磁盘使用率df -h大于10%的行df -h | awk -F'[ %]+' 'NR>1 && $5>=10'[root@nfs01 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 3.3G 0 3.3G 0% /dev tmpfs 3.3G 0 3.3G 0% /dev/shm tmpfs 3.3G 9.2M 3.3G 1% /run tmpfs 3.3G 0 3.3G 0% /sys/fs/cgroup /dev/sda3 97G 4.2G 93G 5% / tmpfs 3.3G 0 3.3G 0% /tmp /dev/sda1 1014M 167M 848M 17% /boot tmpfs 666M 0 666M 0% /run/user/0 [root@nfs01 ~]# df -h | awk -F'[ %]+' 'NR>1 && $5>=10' /dev/sda1 1014M 167M 848M 17% /boot3.4.5.过滤某一列中有什么根据指定的列进行过滤:如果第3列中包含xxxx则显示这一行 sed,grep都是基于行,这一行中有或没有xxxx$xxx~// 匹配,包含$xxx!~// 匹配,不包含/etc/passwd中第3列UID包含0或1,输出这一行的第1列,第3列和最后一列条件:行 第3列包含0或1 动作:列 输出第1列,3列,最后一列 awk -F: '$3~/[01]/ {print $1,$3,$NF}' passwd/etc/passwd中第3列UID包含0或1结尾,输出这一行的第1列,第3列和最后一列awk -F: '$3~/[01]$/ {print $1,$3,$NF}' passwd ^ 某一列的开头 $ 某一列的结尾过滤出access.log中第7列以.jpg或.bmp或.png或.gif结尾的行,统计行数access.log nginx访问日志,只要访问就会有记录第1列 ip地址第7列 用户访问的页面路径第9列 状态码,访问结果正常,异常第10列 页面大小awk '$7~/\.jpg$|\.bmp$|\.gif$|\.png$/' access.log awk '$7~/\.(jpg|bmp|gif|png)$/' access.log awk '$7~/\.jpg$|\.bmp$|\.gif$|\.png$/' access.log |wc -l awk '$7~/\.(jpg|bmp|gif|png)$/' access.log |wc -l3.5.awk计算与统计3.5.1.目标记忆awk两个常用公式使用awk进行求和使用awk进行计算的百分数(一般会与结合取行取列)3.5.2.通过awk实现wc -l效果计数,统计次数未来统计次数的需求,推荐使用wc -lawk '{统计与计算} END{awk读取文件后,才会执行,一般用于输出最后的结果}' xxx i=i+1 i=666 i=i+1 ==== i++ i+1执行,结果写入到i 当前的i 执行i=i+1 之后的i 第1次运行 0 i=0+1 1 第2次运行 1 i=1+1 2 第3次运行 2 i=2+1 3 awk '{i=i+1}END{print i}' calc.txt awk '{i++}END{print i}' calc.txt[root@nfs01 ~]# cat calc.txt |column -t libai 19 wangwu 30 huzi 80 xiaozhang 30 [root@nfs01 ~]# awk '{i++}END{print i}' calc.txt 4 [root@nfs01 ~]# awk '{i=i+1}END{print i}' calc.txt 4 [root@nfs01 ~]# wc -l calc.txt 4 calc.txt[root@nfs01 ~]# awk '{i=i+$2}END{print i}' calc.txt 1593.5.3.统计seq 10结果的总和[root@nfs01 ~]# seq 10 | awk '{sum=sum+$1} END {print sum}' 55access.log是访问日志,日志的第10列,是用户访问的资源的大小,对大小求和,形式以MB或GB形式展示[root@nfs01 ~]# awk '{i=i+$10}END{print i}' access.log 2478496663 [root@nfs01 ~]# awk '{i=i+$10}END{print i/1024/1024"MB"}' access.log 2363.68MB [root@nfs01 ~]# awk '{i=i+$10}END{print i/1024/1024/1024"GB"}' access.log 2.30828GB3.5.4.统计free结果中内存空闲率END{}一般用于数据分散在不同的行,需要使用END{}[root@nfs01 ~]# free total used free shared buff/cache available Mem: 6819580 233096 6226252 9360 360232 6332088 Swap: 2097148 0 2097148 [root@nfs01 ~]# free | awk 'NR==2' Mem: 6819580 232948 6226400 9360 360232 6332236 [root@nfs01 ~]# free | awk 'NR==2{print $NF}' 6332564 [root@nfs01 ~]# free | awk 'NR==2{print $NF/$2*100}' 92.8606 [root@nfs01 ~]# free | awk 'NR==2{print $NF/$2*100"%"}' 92.8625%4.grep:star::star::star::star::star:5.endl -
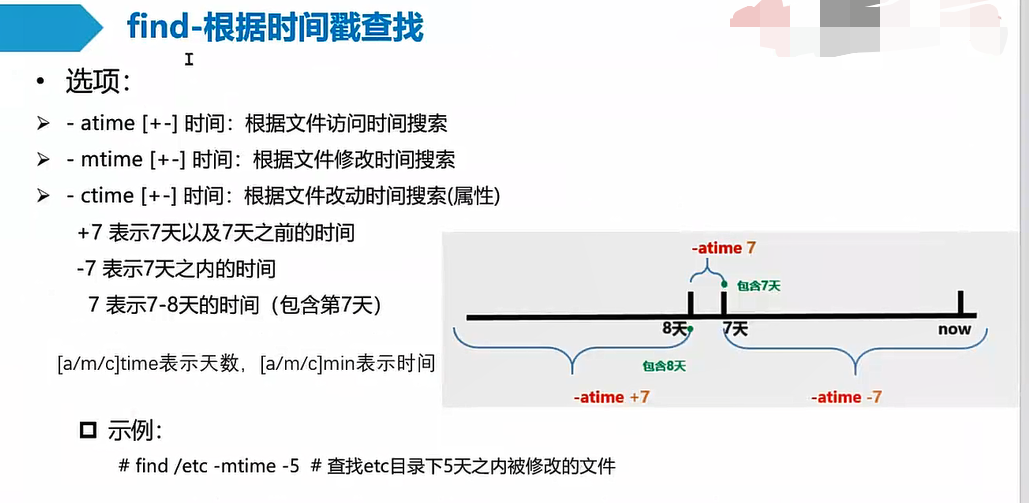
find 按文件修改时间查找文件及find空文件夹 查找两天前修改过的文件:find . -type f -mtime -2查找3天内修改过的文件:find -ctime -3find命令使用超过6天,空文件独立查询命令:find /data/backup -ctime +6 -exec rm -f {} \; 删除/data/backup目录下修改时间超过6天的文件。 find /data/backup -type d -empty -exec rmdir {} \; >/dev/null 2>&1 删除/data/backup目录下空的文件夹,同时输出正确和错误信息到空。查找超过6天且是空文件的find命令:find ./ -type d -empty -ctime +6按修改时间来查找文件,要用到选项-mtime:find /home/admin -mtime -1 #查找/home/admin目录下修改时间在1天之内的文件find /home/admin -name *.txt -mtime -1 #查找/home/admin目录下修改时间在1天之内的文件名为.txt结尾的文件find 按文件修改时间查找文件---(+n)----------|----------(n)----------|----------(-n)--- (n+1)*24H前| (n+1)*24H~n*24H间 |n*24H内 -ctime -n 查找距现在 n*24H 内修改过的文件-ctime n 查找距现在 n24H 前, (n+1)24H 内修改过的文件-ctime +n 查找距现在 (n+1)*24H 前修改过的文件[a|c|m]min [最后访问|最后状态修改|最后内容修改]min[a|c|m]time [最后访问|最后状态修改|最后内容修改]timelinux 文件的三种时间(以 find 为例):atime 最后一次访问时间, 如 ls, more 等, 但 chmod, chown, ls, stat 等不会修改些时间, 使用 ls -utl 可以按此时间顺序查看;ctime 最后一次状态修改时间, 如 chmod, chown 等状态时间改变但修改时间不会改变, 使用 stat file 可以查看;mtime 最后一次内容修改时间, 如 vi 保存后等, 修改时间发生改变的话, atime 和 ctime 也相应跟着发生改变.注意:linux 里是不会记录文件的创建时间的,除非这个文件自创建以来没有发生改变,那么它的创建时间就是它的最后一次修改时间。ls -lt /home/admin # 按修改时间顺序查看ls -lut /home/admin # 按访问时间顺序查看(如果想反序查看的话需要加一个选项 -r)知识点:atime ,ctime ,mtime比如,编辑文件内容并保存,文件内容改变会更新 mtime,同时文件系统因写入操作更新 inode 相关信息,也会导致 ctime 更新由于 ctime 记录的是 inode 节点信息的更改时间,而文件内容修改会导致 inode 信息更新,所以 mtime 的更新通常会伴随 ctime 的更新。但 ctime 更新不一定是因为 mtime 变化,修改文件权限等元数据也会更新 ctime,此时 mtime 不变。
-
Linux三剑客【grep、sed、awk】-02 Linux三剑客【grep、sed、awk】-021. 💓grep文本搜索工具语法结构:参数选项参数选项注释说明-w精确匹配整词-v取反-E扩展正则-i忽略大小写-r递归过滤文件内容-l只显示符合匹配条件的文件名-n显示匹配内容的行号-c只显示匹配的行数-o匹配过程 -A过滤内容,往下显示n行-B过滤内容,往上显示n行-C过滤内容,上下各显示n行2. 💓sed:批量编辑文本文件2.1. sed的作用sed是取行、修改、过滤和替换文本内容的强大工具。常用功能有对文件实现快速的增删改查。2.2. sed命令的语法及参数语法格式:参数选项:参数选项注释说明参数选项注释说明-n取消默认sed输出,常与p连用-r支持扩展正则-i直接修改文件内容-e支持多次修改动作参数:动作参数注释说明动作参数注释说明a增加pprint,打印匹配行内容d删除s替换i插入g全局2.2.1. sed增删改查——查找行案例实践:环境准备: [root@linux:~]# cat -n test.txt 1 I am lizhenya teacher! 2 I teach linux. 3 test 4 5 I like badminton ball ,billiard ball and chinese chess! 6 my blog is http: blog.51cto.com 7 our site is http:www.lizhenya.com 8 my qq num is 593528156 9 10 aaa, 11 not 572891888887. 案例1.sed输出第三行 [root@linux:~]# sed -n '3p' test.txt test 案例2.sed输出最后一行 [root@linux:~]# sed -n '$p' test.txt not 572891888887. 案例3.sed输出第3~5行 [root@linux:~]# sed -n '3,5p' test.txt test I like badminton ball ,billiard ball and chinese chess! 案例4.sed输出第10行到最后一行 [root@linux:~]# sed -n '10,$p' test.txt aaa, not 572891888887.2.2.2. sed增删改查——查找字符串作用:过滤文件的字符串语法结构:sed -n '/字符串/p' 文件sed -n '/[字符串]/p' 文件案例实践:环境准备: [root@linux:~]# head -10 /etc/passwd >passwd.txt [root@linux:~]# cat -n passwd.txt 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 8 halt:x:7:0:halt:/sbin:/sbin/halt 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10 operator:x:11:0:operator:/root:/sbin/nologin 案例1.查找passwd.txt中包含root的行 [root@linux:~]# sed -n '/root/p' passwd.txt root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin 案例2.查找passwd.txt中包含bash的行 [root@linux:~]# sed -n '/bash/p' passwd.txt root:x:0:0:root:/root:/bin/bash 案例3.使用正则,查找以r开头的行 [root@linux:~]# sed -n '/^r/p' passwd.txt root:x:0:0:root:/root:/bin/bash 案例4.查找以n结尾的行 [root@linux:~]# sed -n '/n$/p' passwd.txt bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin 案例5.查找包含root或者sync的行 [root@linux:~]# sed -rn '/root|sync/p' passwd.txt root:x:0:0:root:/root:/bin/bash sync:x:5:0:sync:/sbin:/bin/sync operator:x:11:0:operator:/root:/sbin/nologin 案例6.查找包含或a 或b 或 c的行 [root@linux:~]# sed -rn '/a|b|c/p' passwd.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin 案例7.查找字符串的区间范围使用逗号,查找adm和sync中间的行 [root@linux:~]# sed -rn '/adm/,/sync/p' passwd.txt adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync匹配区间范围注意:(1)如果有两个结尾只匹配到第一个结尾终止(2)如果只有开头,没有匹配到结尾,则输出开头到文件末尾2.2.3. sed增删改查——删除实践案例:环境准备: [root@linux:~]# cat -n a.txt 1 111111 2 222222 3 333333 4 444444 5 555555 6 666666 案例1.指定行删除 [root@linux:~]# sed '3d' a.txt 111111 222222 444444 555555 666666 案例2.删除3~5行 [root@linux:~]# sed '3,5d' a.txt 111111 222222 6666662.2.4. sed增删改查——增加语法结构:sed '3c test' file #将第三行替换成testsed '3i test ' file #在第三行处插入test字符串sed '3a test' file #在第三行的下面追加test字符串实践案例:环境准备: [root@linux:~]# cat -n passwd.txt 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 8 halt:x:7:0:halt:/sbin:/sbin/halt 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10 operator:x:11:0:operator:/root:/sbin/nologin 案例: 将第3行替换成test [root@linux:~]# sed '3c test' passwd.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin test adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin 案例2.在第3行插入test字符串 [root@linux:~]# sed '3i test' passwd.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin test daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin 案例3.在第3行处追加test字符串 [root@linux:~]# sed '3a test' passwd.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin test adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin2.2.5. sed增删改查——替换语法结构:sed 's#root#xiaozhou #g' filesed 's///g' filesed 's@@@g' file实践案例:环境准备: [root@linux:~]# cat -n passwd.txt 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 8 halt:x:7:0:halt:/sbin:/sbin/halt 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10 operator:x:11:0:operator:/root:/sbin/nologin 案例1.将root全部替换为xiaozhou [root@linux:~]# sed 's#root#xiaozhou#g' passwd.txt xiaozhou:x:0:0:xiaozhou:/xiaozhou:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/xiaozhou:/sbin/nologin 案例2.将文件开头全部替换成# “批量注释” [root@linux:~]# sed 's/^/#/g' passwd.txt #root:x:0:0:root:/root:/bin/bash #bin:x:1:1:bin:/bin:/sbin/nologin #daemon:x:2:2:daemon:/sbin:/sbin/nologin #adm:x:3:4:adm:/var/adm:/sbin/nologin #lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin #sync:x:5:0:sync:/sbin:/bin/sync #shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown #halt:x:7:0:halt:/sbin:/sbin/halt #mail:x:8:12:mail:/var/spool/mail:/sbin/nologin #operator:x:11:0:operator:/root:/sbin/nologin 案例3.只替换每行的第一个root为xiaozhou [root@linux:~]# sed 's/root/xiaozhou/' passwd.txt xiaozhou:x:0:0:root:/root:/bin/bash 案例4.将第三行的a替换为A [root@linux:~]# sed '3s/a/A/g' passwd.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin dAemon:x:2:2:dAemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin 案例5.第3-5行小a替换成A [root@linux:~]# sed '3,5s/a/A/g' passwd.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin dAemon:x:2:2:dAemon:/sbin:/sbin/nologin Adm:x:3:4:Adm:/vAr/Adm:/sbin/nologin lp:x:4:7:lp:/vAr/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin 案例6.将包含root的行 将bash 替换成test [root@linux:~]# sed '/root/s/bin/test/g' passwd.txt root:x:0:0:root:/root:/test/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/stest/nologin 案例7.只替换bin为test [root@linux:~]# sed 's#\bbin\b#test#g' passwd.txt root:x:0:0:root:/root:/test/bash test:x:1:1:test:/test:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/test/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin 案例8.替换passwd.txt中所有的字符 [root@linux:~]# sed 's#[0-Z]##g' passwd.txt :::::/:// :::::/:// :::::/:// ::::://:// :::::///:// :::::/:// :::::/:// :::::/:// :::::///:// :::::/://一、awk技巧💞1.语法结构取行: awk 'NR==3' file取列: awk '{print $3} ' file****同时取行取列: awk 'NR==3{print $3}' file取出含有某个字符串的行:awk '/字符串/' file区间范围 :awk '/字符串/,/字符串/' file2.使用awk命令获取文本的某一列技巧#打印文件的第一列 awk '{print $1}' filename #打印文件的前两列 awk '{print $1,$2}' filenameNR 存放每行的行号NF 存放最后一列的列号$NF 取最后一列******$(NF-N) 取倒数第几列$0 取所有列的信息(取所有行)3.awk 获取某些列的某些行(打印或不打印第几行)#打印文本的第一行 awk 'NR==1' filename #取test.txt文件中的第1,2列,不打印第一行 awk 'NR!=1 {print $1,$2}' test.txt #取test.txt文件中的第2行的第3列 awk 'NR==2 {print $3}' test.txt #输出小于3的行 awk 'NR<3' passwd.txt #查找大于2并且小于6的行 awk 'NR>2&&NR<6' passwd.txt #查找小于2或者大于5的行 awk 'NR<2||NR>5' passwd.txt NR==n 表示打印第n行NR!=n 表示不打印第n行&& 并且|| 或者4.使用awk命令取某一行数据中的倒数第N列#取/etc/passwd文件中的第2列、倒数第1、倒数第2、倒数第4列(以冒号为分隔符) awk -F":" '{print $2,$NF,$(NF-1),$(NF-2),$(NF-3)}' /etc/passwd参数:-F 指定分隔符5.使用awk命令取包含某个字符串的行#查找包含root的行 awk '/root/' passwd.txt #区间范围 awk '/adm/,/sync/' passwd.txt #找出第一列是oldboy的行 awk '$1=="oldboy"' b.txt 6.awk中的"匹配"与"不匹配"[root@kevin~]# cat test.txt afjdkj 80 lkdjfkja 8080 dfjj 80 jdsalfj 808080 jasj 80 jg 80 linuxidc 80 80 ajfkj asf 80 80 linuxidc wang bo kevin grace ha 80880 #打印上面test文件中第二列匹配80开头并以80结束的行 [root@kevin~]# awk '{if($2~/^80$/)print}' test.txt afjdkj 80 dfjj 80 jasj 80 jg 80 linuxidc 80 asf 80 #打印上面test文件中第二列中不匹配80开头并以80结束的行 [root@kevin~]# awk '{if($2!~/^80$/)print}' test.txt lkdjfkja 8080 jdsalfj 808080 80 ajfkj 80 linuxidc wang bo kevin grace ha 80880 #打印上面test文件中第二列是"bo"的行 [root@kevin~]# cat test.txt |awk '{if($2=="bo")print}' wang bo~ 匹配正则 !~ 不匹配正则 == 等于 != 不等于7.AWK的内置变量(NF、NR、FNR、FS、OFS、RS、ORS)NF 字段个数,(读取的列数) NR 记录数(行号),从1开始,新的文件延续上面的计数,新文件不从1开始 FNR 读取文件的记录数(行号),从1开始,新的文件重新从1开始计数 FS 输入字段分隔符,默认是空格 OFS 输出字段分隔符 默认也是空格 RS 输入行分隔符,默认为换行符 ORS 输出行分隔符,默认为换行符二、sed技巧💞1.语法结构取第3行: sed -n '3p' file 取最后一行: sed -n '$p' file 取3~5行: sed -n '3,5' file 取第3行到最后一行: sed -n '3,$p' file 查找包含某字符串的行: sed -n '/字符串/p' file 查找以a开头的行: sed -n '/^a/' file 查找以a结尾的行: sed -n '/a$/' file 将第三行替换成test: sed '3c test' file 第三行处插入test字符串: sed '3i test ' file 在第三行的下面追加test字符串:sed '3a test' file 将内容替换成XXX: sed 's#内容#替换成#g' file sed '2s#xx#xx#g' sed '//s#xx#xx#g' file2.参数选项-n 取消默认sed输出 (与p连用)-r 支持扩展正则-i 直接修改文件的内容3.动作参数a 增加ci 插入d 删除4.查找第几行#sed输出第三行 sed -n '3p' test.txt #sed输出最后一行 sed -n '$p' test.txt #sed输出第3~5行 sed -n '3,5p' test.txt #sed输出第10行到最后一行 sed -n '10,$p' test.txt 5.查找包含字符串的行#查找passwd.txt中包含root的行 sed -n '/root/p' passwd.txt #查找passwd.txt中包含bash的行 sed -n '/bash/p' passwd.txt #使用正则,查找以r开头的行 sed -n '/^r/p' passwd.txt #查找以n结尾的行 sed -n '/n$/p' passwd.txt #查找包含root或者sync的行 sed -rn '/root|sync/p' passwd.txt #查找包含或a 或b 或 c的行 sed -rn '/a|b|c/p' passwd.txt #查找字符串的区间范围使用逗号,查找adm和sync中间的行 sed -rn '/adm/,/sync/p' passwd.txt 6.删除指定行#删除第3行 sed '3d' a.txt #删除3~5行 sed '3,5d' a.txt7.替换#将root全部替换为xiaozhou sed 's#root#xiaozhou#g' passwd.txt #将文件开头全部替换成# “批量注释” sed 's/^/#/g' passwd.txt #只替换每行的第一个root为xiaozhou (后边不要加g,,只替换每行的第一个) sed 's/root/xiaozhou/' passwd.txt #将第三行的a替换为A sed '3s/a/A/g' passwd.txt #第3-5行小a替换成A sed '3,5s/a/A/g' passwd.txt #将包含root的行 将bash 替换成test sed '/root/s/bin/test/g' passwd.txt #只替换bin为test sed 's#\bbin\b#test#g' passwd.txt #替换passwd.txt中所有的字符 sed 's#[0-Z]##g' passwd.txt /b字符串/b 边界/<字符串/> 边界8.后向引用#使用后向引用取出IP地址 ifconfig ens33|sed -rn '2s#^.*inet (.*) netmask.*#\1#gp' #取出IP地址和子网掩码 ifconfig ens33|sed -rn '2s#^.*inet (.*) netmask (.*) bro.*$#\1\2#gp'三、 grep技巧💞1.语法结构grep 参数 '字符串' file2.参数选项-n 显示匹配内容的行号-r 递归过滤文件-w 匹配整词-v 取反-o 显示匹配过程-E 支持扩展正则 ==egrep四、awk/grep/awk区别对比💫💯💨 grepsedawk参数选项-n 显示匹配内容的行号-r 递归过滤文件-w 匹配整词-v 取反-o 显示匹配过程-E 支持扩展正则egrep-n 取消默认sed输出(与p连用)-r 支持扩展正则-i 直接修改文件的内容-F 指定分隔符取行grep 参数 "字符串" filesed -n '3p' filesed -n '$p' fileawk 'NR==3' fileawk 'NR!=3' file取列 awk '{print $3}' file<br />awk '{print $NF}' fileawk '{print $(NF-1)}' file<br />awk 'NR==5{print $3}' file按字符串查找grep 参数 "字符串" filesed -n '/root/p' filesed -rn '/root/,/adm/p' filesed -rn '/root\adm/p' fileawk '/root/' fileawk '/root/,/adm/' fileawk '/root\adm/' file查找替换 sed '2s#a#A#g' filesed '/root/s#a#A#g' file 后向引用 ifconfig ens33\sed -rn '2s#^.*inet (.*) netmask.*#\1#gp' 其他 动作参数:a 增加c 替换i 插入d 删除NR 存放每行的行号NF 存放最后一列的列号$NF 取最后一列<br />$(NF-N) 取倒数第几列$0 取所有列的信息(取所有行)endl
-
Linux三剑客【grep、sed、awk】-01 Linux三剑客【grep、sed、awk】-01Linux三剑客是什么?linux中的文本处理三剑客分别是grep、awk、sed,它们都以正则表达式作为基础,而在Linux系统中,支持两种正则表达式,分别为"标准正则表达式"和"扩展正则表达式",正则表达式的内容我们后续会讲,首先我们先明确一下三剑客的特点及应用场景,如下表所示:命令特点应用场景grep文本过滤包括从文件中进行过滤和从标准输入进行过滤,其过滤速度最快sed取行文件内容新增、删除、替换、取出某个范围的内容awk取列编写awk脚本对文本进行格式化输出(可进行统计计算)grep:主要用于文本内容查找,支持正则表达式。sed:主要用于文本内容的编辑,默认只处理模式空间,不改变原数据,而且sed使用逐行模式读取的方式处理数据。awk:主要用于文本内容的分析处理,也常用于处理数据,生成报告,非常适用于需要按列处理的数据。grep-搜索指定的内容grep命令用于在文本文件中搜索指定的内容,并返回匹配的行。以下是grep命令的10个用法案例:含义表达式搜索包含指定关键词的行grep "keyword" file.txt忽略大小写的关键词grep -i "keyword" file.txt不显示匹配的行grep -v "keyword" file.txt统计匹配行的数量grep -c "keyword" file.txt显示匹配行之前的内容grep -B 2 "keyword" file.txt显示匹配行之后的内容grep -A 2 "keyword" file.txt显示匹配行及其上下文的内容grep -C 2 "keyword" file.txt把每个匹配的内容用独立的行显示grep -o "keyword" file.txt递归搜索目录 及其子目录下的文件grep -r "keyword" directory使用扩展正则表达式进行高级搜索grep -E "pattern" file.txtgrep示例Shell脚本代码ps -ef | grep bash echo "ABC" | grep -i abc ps -ef | grep bash | grep -v bash echo "1234 7654" | grep -o "[0-9]4" echo "1234 7654" | grep -oE "[0-9]4|76"grep实战演练题目找出nginx.log中所有404和503报错的log数据,取出前3条数据,把命令贴到回复里。找出testerhome首页的所有http和https的链接。sed-流式编辑sed命令用于对文本进行流式编辑,可以进行替换、删除、插入等操作。以下是sed命令的10个用法举例:含义表达式替换文本中的指定字符串sed 's/old/new/' file.txt替换文本中的所有匹配字符串sed 's/old/new/g' file.txt删除匹配指定模式的行sed '/pattern/d' file.txt删除空白行sed '/^$/d' file.txt在匹配行之前插入新行sed '/pattern/i new line' file.txt在匹配行之后插入新行sed '/pattern/a new line' file.txt仅打印匹配的行sed -n '/pattern/p' file.txt仅打印指定行范围内的内容sed -n '2,5p' file.txt将文本中的所有字母转为大写sed 's/[a-z]/\U&/g' file.txt将文本中的所有字母转为小写sed 's/[a-z]/\L&/g' file.txtsed pattern表达式20,30,35 行数与行数范围/pattern/正则匹配//,//正则匹配的区间actiond删除p打印,通常结合-n参数s/REGXP/REPLACEMENT/[FLAGS]替换时引用\1 \2 匹配的字段sed示例Shell脚本代码ps | sed -n 1,3p ps | sed 's/CMD/command/' ps | sed -n '/ps/p' echo '1 2 3 4 5' | sed -n '/3/,/4/p' echo '1 2 3 4 5' | sed '/3/,/4/d' ps | sed -e 's/CMD/command/' -e 's#00#20#g'awk-文本处理awk命令式一种强大的文本处理工具,可以根据指定的规则从文本中提取信息并进行处理。以下是awk命令的10个用法举例:含义表达式打印指定列的内容awk '{print $1}' file.txt根据指定的分隔符切割文本并打印指定列awk -F',' '{print $2}' file.txt根据指定条件筛选行并打印awk '/pattern/{print}' file.txt计算指定列的总和awk '{sum+=$1}END{print sum}' file.txt根据指定条件进行行和列的求和awk '{rowsum+=$1;colsum+=$2}END{print rowsum,colsum}' file.txt根据 指定条件进行行的分组并计数awk '{count[$1]++}END{for (item in count) print item,count[item]}' file.txt根据指定条件进行行的分组并求平均值awk '{sum[$1]+=$2;count[$1]++}END{for (item in sum)print item,sum[item]/count[item]}' file.txt格式化输出awk '{print "%-10s %-5d\n",$1,$2}' file.txt自定义变量 并进行计算awk 'BEGIN{x=5;y=10;print x+y}'执行自定义函数awk 'function myfunc(x) {return x*2}{print myfunc($1)}' file.txtawk pattern语法awk理论上可以代替grepawk 'pattern{action}'awk 'BEGIN{}END{}' 开始和结束awk '/Running/' 正则匹配awk '/aa/,/bb/' 区间选择awk '$2~/xxx/' 字段匹配awk 'NR==2' 取第二行awk 'NR>1' 去掉第一行awk的字段数据处理-F参数指定字段分隔符BEGIN{FS="_"} 也可以表示分隔符$0代表原来的行$1代表第一个字段$N代表第N个字段$NF代表最后一个字段awk行处理把单行分拆为多行echo $PATH | awk 'BEGIN{RS=":"} {print $0}'echo $PATH | awk 'BEGIN{RS=":"} {print NR,$0}'echo $PATH | awk 'BEGIN{RS=":"} {print NR}'多行组合为单行echo $PATH | awk 'BEGIN{RS=":"} {print $0}' | awk 'BEGIN{FS="\n";ORS=":"} {print $0}'awk示例Shell脚本代码ps | awk 'BEGIN{print "start"} {print $0} END {print "end"}' awk '/404 | 500 /' /usr/local/nginx/log/nginx.log echo '1 2 3 4 5' | awk '/2/,/4/' echo '1 2 3 4 5' | awk '$0>3' ps | awk 'NR>1' ps | awk '{print $NF}' echo $PATH | awk 'BEGIN{RS=":"} {print $0}' | grep -v "^$" | awk 'BEGIN{FS="\n";ORS=":"} {print $0} END {printf "\n"}' echo '1,10 2,20 3,30' | awk 'BEGIN{a=0;FS=","} {a+=$2} END {print a,a/R}' awk 'BEGIN{print 33*20*76/200/3}' echo "123|456_789" | awk 'BEGIN{FS="\\||_"} {print $2}' echo "123|456_789" | awk 'BEGIN{FS=\"\\\\||_\"} {print \$2}' #尽量使用单引号awk实战演练题目找出404和503的数据,只打印状态码这一列,然后排序去重,把命令贴到回复里。找出testerhome首页找到所有的http的链接,然后打印不带http的纯域名部分。endl