搜索到
10
篇与
的结果
-
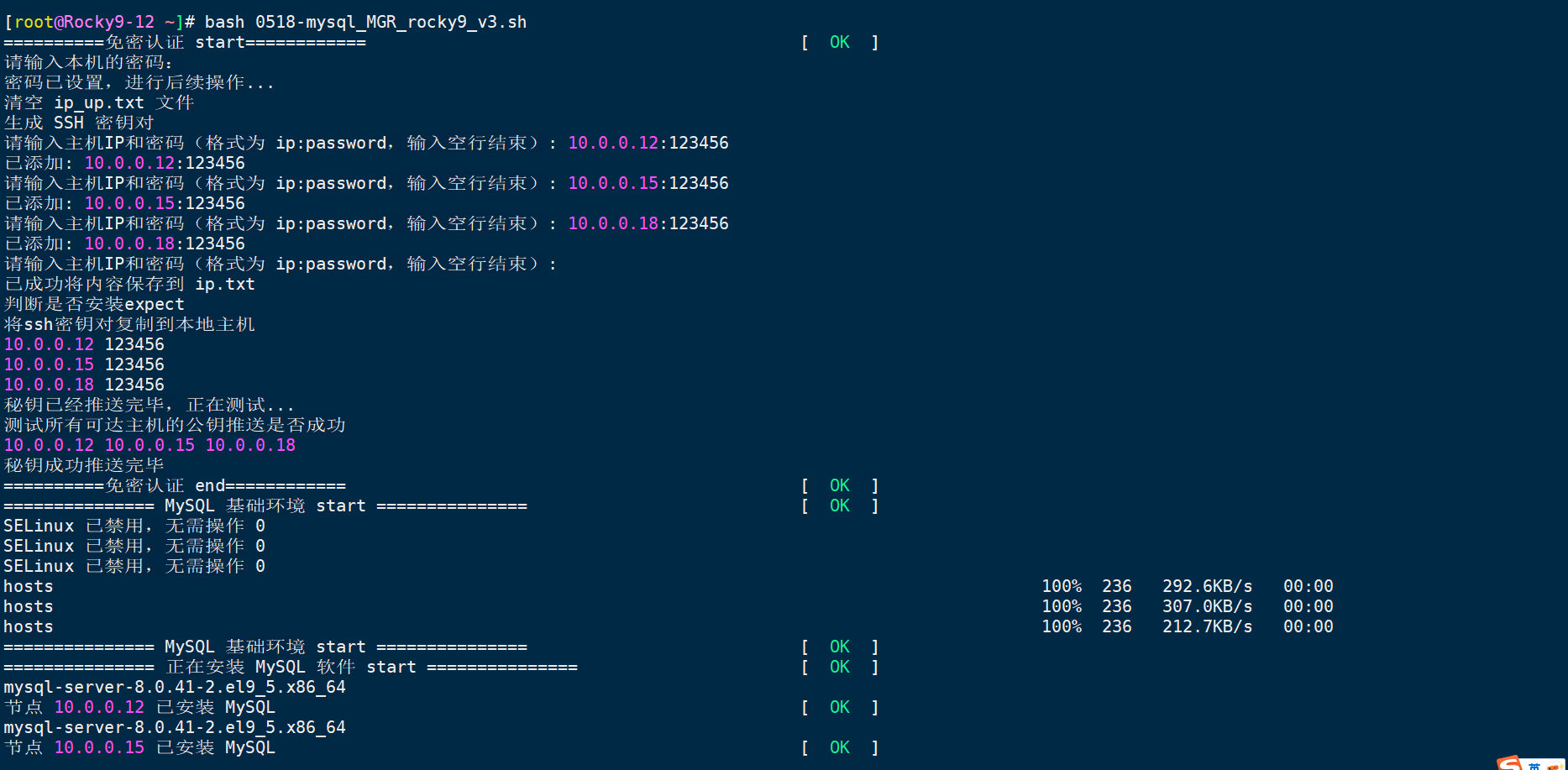
 MGR集群auto认证脚本 MGR集群auto认证脚本#!/bin/bash # ************************************* # * 功能: Shell脚本模板 # * 作者: 刘丹玉 # * 联系: v649352141@163.com # * 版本: 2025-05-18 # ************************************* # 错误处理:如果命令执行失败,脚本将终止 set -e # 调试处理 # set -x MYSQL_PWD="Mysql.123456" MYSQL_VERION="8.0.41" MYSQL_PORT="3306" PORT="33061" OS_NAME="Rocky" MY_UUID=$(uuidgen) # 预定义主机列表 #HOSTS=("10.0.0.12" "10.0.0.15" "10.0.0.18") HOSTS=() PRIMARY_HOST="10.0.0.12" # 集群总节点数n ONLINE_COUNT="${#HOSTS[@]}" # 颜色脚本,通用 color () { RES_COL=80 MOVE_TO_COL="echo -en \\033[${RES_COL}G" SETCOLOR_SUCCESS="echo -en \\033[1;32m" SETCOLOR_FAILURE="echo -en \\033[1;31m" SETCOLOR_WARNING="echo -en \\033[1;33m" SETCOLOR_NORMAL="echo -en \E[0m" echo -n "$1" && $MOVE_TO_COL echo -n "[" if [[ $2 = "success" || $2 = "0" ]] ;then ${SETCOLOR_SUCCESS} echo -n $" OK " elif [[ $2 = "failure" || $2 = "1" ]] ;then ${SETCOLOR_FAILURE} echo -n $"FAILED" else ${SETCOLOR_WARNING} echo -n $"WARNING" fi ${SETCOLOR_NORMAL} echo -n "]" echo } # 查看属于Rocky、Ubuntu、openEuler系列 os_type () { $OS_NAME=$(awk -F'[ "]' '/^NAME/{print $2}' /etc/os-release) } # 免密认证 pwd_auth_across_host(){ color "==========免密认证 start============" 0 # 设置本机ip和密码 #read -s -p "请输入本机的密码:" secret read -p "请输入本机的密码:" secret echo # 换行,让后续输出从新行开始 # 检查密码是否为空 if [ -z "$secret" ]; then echo "错误:密码不能为空!" >&2 exit 1 fi # 可选:使用密码进行后续操作 echo "密码已设置,进行后续操作..." echo "清空 ip_up.txt 文件" > ip_up.txt # 生成 SSH 密钥对,不输出信息到屏幕 echo "生成 SSH 密钥对" ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa > /dev/null 2>&1 # 循环读取用户输入 while true;do read -p "请输入主机IP和密码(格式为 ip:password,输入空行结束): " str # 检查是否为空行(用户想结束输入) if [ -z "$str" ]; then break fi # 将输入追加到ip_up.txt echo "$str" >> ip.txt echo "已添加: $str" done # 检查是否添加了任何内容 if [ -s "ip.txt" ]; then echo "已成功将内容保存到 ip.txt" else exit 1 fi echo "判断是否安装expect" ! rpm -q expect &>/dev/null && { echo "未安装 expect,正在尝试安装..."; yum -y install expect &>/dev/null || { echo "错误:expect 安装失败,请检查网络连接或权限" >&2; exit 1; }; } echo "将ssh密钥对复制到本地主机" # 使用 expect 实现 ssh-copy-id 到本地主机 /usr/bin/expect <<-END &>/dev/null spawn ssh-copy-id 127.1 expect { "yes/no" { send "yes\r"; exp_continue } "password:" { send "$secret\r" } timeout { puts "连接 127.0.0.1 超时,推送失败。" exit 1 } eof { if { [exp_status] != 0 } { puts "向 127.0.0.1 推送公钥失败。" exit 1 } } } expect eof END # 循环判断主机是否 ping 通,如果 ping 通则推送秘钥对 while IFS=: read -r ip pass; do # 检查读取的行是否符合格式 if [ -z "$ip" ] || [ -z "$pass" ]; then echo "ip.txt 文件中存在格式错误的行:$ip:$pass" continue fi ping -c1 $ip &>/dev/null if [ $? -eq 0 ];then echo $ip $pass echo $ip $pass >> ip_up.txt /usr/bin/expect <<-END &>/dev/null spawn rsync -avz /root/.ssh/ $ip:/root/.ssh/ expect { "yes/no" { send "yes\r";exp_continue } "password:" { send "$pass\r" } timeout { puts "连接 $ip 超时,推送失败。" exit 1 } eof { if { [regexp -nocase "Permission denied" \$expect_out(buffer)] } { puts "认证失败: $ip" exit 1 } else { puts "密钥推送成功: $ip" exit 0 } } } expect eof END fi done < ip.txt wait echo "秘钥已经推送完毕,正在测试..." echo "测试所有可达主机的公钥推送是否成功" all_success=true while read -r line; do remote_ip=$(echo "$line" | cut -d' ' -f1) ssh root@"$remote_ip" hostname &>/dev/null if [ $? -ne 0 ]; then echo "向 $remote_ip 推送公钥失败。" all_success=false fi done < ip_up.txt # 或从文件读取(确保文件每行一个主机名) HOSTS=() while IFS= read -r line; do # 过滤掉空行 if [[ -n "$line" ]]; then # 提取每行的第一个字段(以空格分隔) host=$(echo "$line" | cut -d' ' -f1) # 正确添加到数组 HOSTS+=("$host") fi done < ip_up.txt echo ${HOSTS[@]} PRIMARY_HOST="${HOSTS[0]}" if $all_success; then echo "秘钥成功推送完毕" else echo "部分主机公钥推送失败,请检查。" fi color "==========免密认证 end============" 0 } # 基础环境 base_environment(){ color "=============== MySQL 基础环境 start ===============" 0 for host in "${HOSTS[@]}"; do # 获取ip最后一位 last_octet=${host##*.} # 获取数组索引(正确方式) for i in "${!HOSTS[@]}"; do if [[ "${HOSTS[$i]}" == "$host" ]]; then index=$i break fi done name="rocky9-$last_octet-mgr0$((index + 1))" # 修改主机名 ssh root@$host "hostnamectl set-hostname $name" # 配置主机名称解析 echo $host $name >> /etc/hosts sleep 1 # 临时关闭SELINUX ssh root@10.0.0.12 ' if grep -q "SELINUX=enforcing" /etc/selinux/config; then setenforce 0 else echo "SELinux 已禁用,无需操作" 0 fi ' # 永久关闭SELINUX ssh root@$host "sed -i.bak 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config" sleep 1 # 临时关闭防火墙 ssh root@$host "systemctl disable --now firewalld && nft flush ruleset" done for host in "${HOSTS[@]}"; do scp /etc/hosts root@$host:/etc/hosts done color "=============== MySQL 基础环境 end ===============" 0 } # 安装并启动 MySQL 服务 install_mysql_soft() { color "=============== 正在安装 MySQL 软件 start ===============" 0 for host in "${HOSTS[@]}"; do # 检查是否已安装 if ! ssh root@"$host" "rpm -q mysql-server";then color "节点 $host 未安装 MySQL,开始安装..." 2 if ssh root@"$host" "yum -y install mysql-server >/dev/null 2>&1";then color "节点 $host MySQL 安装成功!" 0 else color "错误:节点 $host MySQL 安装失败!" 2 fi else color "节点 $host 已安装 MySQL" 0 fi sleep 1 done color "=============== 正在安装 MySQL 软件 end ===============" 3 } # 检查Mysql是否启动 check_mysql_is_active(){ color "=============== 正在测试 MySQL 是否存活 ===============" 0 for host in "${HOSTS[@]}"; do # 检查服务状态 if ! ssh root@"$host" "systemctl is-active mysqld"; then # 尝试重启 if ssh root@"$host" "systemctl restart mysqld && systemctl enable mysqld" >/dev/null 2>&1; then color "节点 $host MySQL 服务已启动并设置为开机自启!" 0 else color "错误:节点 $host MySQL 服务启动失败!" 2 fi fi sleep 1 done sleep 2 color "=============== MySQL 状态检查完成 ===============" 0 } # 正在测试 MySQL 是否存活 check_mysql_status(){ color "=============== 正在测试 MySQL 是否存活 start ============" 0 for host in "${HOSTS[@]}"; do # 使用 mysqladmin ping 检查连接状态 if ssh root@"$host" "mysqladmin ping -h localhost -uroot -p'$MYSQL_PWD' --silent" >/dev/null 2&>1; then color "节点 $host MySQL 服务已运行且可连接" 0 else # 检查Mysql是否启动 check_mysql_is_active color "节点 $host MySQL 无响应,尝试重启..." 1 fi done color "=============== 正在测试 MySQL 是否存活 end ============" 0 } # 修改mysql密码 alter_mysql_pwd() { color "========正在修改mysql密码 start ======" 0 for host in "${HOSTS[@]}"; do color "正在修改主机 $host 的 MySQL 密码..." 0 # 使用当前密码执行 SQL 命令 ssh root@"$host" "mysql -e \"ALTER USER root@'localhost' IDENTIFIED BY '$MYSQL_PWD';\"" color "节点 $host MySQL 服务密码已修改" 0 sleep 1 done sleep 2 color "=========正在修改mysql密码 end ========" 0 # 检查mysql连接状态 check_mysql_status } get_mysql_version() { color "========正在获取mysql版本信息 start =======" 0 # 定义获取版本的 SQL 命令 local SQL_COMMAND="SELECT VERSION();" # 遍历所有主机获取 MySQL 版本 for host in "${HOSTS[@]}"; do color "正在获取主机 $host 的 MySQL 版本..." 0 # 通过 SSH 执行 MySQL 命令并获取版本 local version=$(ssh root@"$host" "mysql -u root -p'$MYSQL_PWD' --batch --skip-column-names <<EOF $SQL_COMMAND EOF") # 检查命令是否成功执行 if [[ $? -ne 0 || -z "$version" ]]; then color "错误:无法获取主机 $host 的 MySQL 版本!" 2 continue fi # 显示版本信息 color "主机 $host 的 MySQL 版本为: $version" 0 # 短暂延迟,避免并发查询过多 sleep 2 done sleep 2 color "=======正在获取mysql版本信息 end ========" 0 } # 配置文件 mysql_config(){ color "=======正在集群配置文件 start =======" 0 # 格式化并拼接 hosts_with_port=$(printf "%s:$PORT,\n" "${HOSTS[@]}" | tr -d '\n' | sed 's/,$//') for host in "${HOSTS[@]}";do color "$host 主机正在写入配置文件" last_octet=$(echo $host | awk -F'.' '{print $4}') ssh root@$host <<- EOF cat > /etc/my.cnf.d/mysql-server.cnf <<- 'eof' [mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock log-error=/var/log/mysql/mysqld.log pid-file=/run/mysqld/mysqld.pid # 为了版本兼容性,更改默认的用户认证插件 default_authentication_plugin=mysql_native_password # 设置MySQL插件目录:MGR基于插件,必须设置插件路径 plugin_dir=/usr/lib64/mysql/plugin # 复制框架 server_id=$last_octet # 开启binlog的GTID模式(MGR强制要求) gtid_mode=ON # 开启后MySQL只允许能够保障事务安全,并且能够被日志记录的SQL语句被执行 enforce_gtid_consistency=ON # 关闭binlog校验(MGR强制要求) binlog_checksum=NONE log_bin=binlog log_slave_updates=ON binlog_format=ROW master_info_repository=TABLE relay_log_info_repository=TABLE # 组复制设置 # server必须为每个事务收集写集合,并使用XXHASH64哈希算法将其编码为散列 transaction_write_set_extraction=XXHASH64 # 启用组复制模块 plugin_load_add='group_replication.so' # 告知插件加入或创建组命名,UUID group_replication_group_name="$MY_UUID" # server启动时不自启组复制,为了避免每次启动自动引导具有相同名称的第二个组,所以设置为OFF。 group_replication_start_on_boot=off # 告诉插件使用IP地址,端口33061用于接收组中其他成员转入连接 # 注意:此处可以使用ip地址,也可以使用主机名方式 group_replication_local_address="$host:$PORT" # 启动组server,种子server,加入组应该连接这些的ip和端口;其他server要加入组得由组成员同意 # 注意:此处可以使用ip地址,也可以使用主机名方式 group_replication_group_seeds="$hosts_with_port" # 配置此服务器为引导组,这个选项必须仅在一台服务器上设置, # 并且仅当第一次启动组或者重新启动整个组时。成功引导组启动后,将此选项设置为关闭。 group_replication_bootstrap_group=off # 指定当前节点向集群其他成员报告的自身的主机名或 IP 地址,用于成员间通信和连接 # 这是保证集群成员间正确通信的基础配置。 report_host=$host report_port=$MYSQL_PORT eof EOF done # 重启MySQL服务 for host in "${HOSTS[@]}"; do ssh root@$host systemctl restart mysqld sleep 1 done sleep 2 color "=======正在集群配置文件 end ========" 0 } # 集群认证环境 cluster_auth_init_sql(){ color "=======正在集群认证环境 start ========" 0 # SQL 脚本内容 SQL_SCRIPT=$(cat <<-'EOF' # 如下操作不记录二进制日志 SET SQL_LOG_BIN=0; # 创建rpl_user账户,此账户用于实现主从数据同步 CREATE USER rpl_user@'%' IDENTIFIED BY '123456'; GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%'; GRANT CONNECTION_ADMIN ON *.* TO rpl_user@'%'; GRANT BACKUP_ADMIN ON *.* TO rpl_user@'%'; GRANT GROUP_REPLICATION_STREAM ON *.* TO rpl_user@'%'; # 创建一个远程连接用户,便于图形化管理工具使用 create user 'remote'@'%' identified with mysql_native_password by '123456'; grant all privileges on *.* to remote@'%'; FLUSH PRIVILEGES; # 恢复二进制日志功能并且重置二进制日志 SET SQL_LOG_BIN=1; RESET MASTER; EOF ) # 循环执行 for host in "${HOSTS[@]}"; do color "$host 主机正在集群认证" 0 # 通过 SSH 执行 MySQL 命令 ssh root@$host "mysql -u root -p'$MYSQL_PWD' <<EOF $SQL_SCRIPT EOF" if [ $? -eq 0 ]; then color "主机 $host 执行集群认证成功!" 0 else color "主机 $host 执行集群认证失败!" 2 fi done color "=======正在集群认证环境 end =======" 0 } # 获取集群的MEMBER_STATE状态信息:OFFLINE离线状态、ONLINE在线状态、RECOVERING恢复状态、UNREACHABLE不可达状态、ERROR错误状态 # 检查集群状态信息 check_cluster_online_exists() { color "=====正在检查集群状态信息 start ======" 0 local total_online=0 local host_count=${#HOSTS[@]} # 循环执行 for host in "${HOSTS[@]}"; do color "正在检查主机 $host 的集群状态..." 0 # 获取当前主机看到的在线节点数 ONLINE_COUNT=$(ssh root@"$host" "mysql -u root -p'$MYSQL_PWD' -Ns -e ' SELECT COUNT(*) FROM performance_schema.replication_group_members WHERE MEMBER_STATE = \"ONLINE\" '") # 验证查询结果是否有效 if [[ -z "$ONLINE_COUNT" || "$ONLINE_COUNT" -lt 0 ]]; then color "错误:无法从主机 $host 获取有效集群状态!" 1 continue fi color "主机 $host 报告:集群中有 $ONLINE_COUNT 个节点在线" 0 # 记录最大在线节点数(避免因网络分区导致部分节点看到不同结果) if [[ "$ONLINE_COUNT" -gt "$total_online" ]]; then total_online="$ONLINE_COUNT" fi sleep 1 done sleep 2 # 判断集群状态 if [[ "$total_online" -eq 0 ]]; then color "错误:集群中没有在线节点,集群处于离线状态!" 2 elif [[ "$total_online" -lt "$host_count" ]]; then color "警告:集群不完整!总节点数: $host_count, 在线节点: $total_online" 2 else color "成功:所有 $total_online 个节点均在线,集群状态正常!" 0 fi color "======正在检查集群状态信息 end =======" 0 } # 检查集群中是否存在 PRIMARY 节点 check_cluster_primary_exists() { color "=====正在检查集群中是否存在 PRIMARY 节点 start =====" 0 local total_primary=0 local host_count=${#HOSTS[@]} # 遍历所有主机,统计 PRIMARY 节点总数 for host in "${HOSTS[@]}"; do color "正在检查主机 $host 的 PRIMARY 节点..." 1 # 获取当前主机视角的 PRIMARY 节点数(单主模式下应为 1) local primary_count=$(ssh root@"$host" "mysql -u root -p'$MYSQL_PWD' -Ns -e ' SELECT COUNT(*) FROM performance_schema.replication_group_members WHERE MEMBER_STATE = \"ONLINE\" AND MEMBER_ROLE = \"PRIMARY\" '") # 验证结果有效性 if [[ -z "$primary_count" || ! "$primary_count" =~ ^[0-9]+$ ]]; then color "错误:主机 $host 返回无效数据!" 2 continue fi color "主机 $host 报告:PRIMARY 节点数 = $primary_count" 1 # 累加 PRIMARY 节点数(正常情况下所有主机的统计应一致) ((total_primary += primary_count)) sleep 1 done sleep 2 # 判断集群 PRIMARY 节点状态 if [[ "$total_primary" -eq 0 ]]; then color "错误:集群中没有 ONLINE 状态的 PRIMARY 节点!" 2 #return 1 # 返回失败状态码 elif [[ "$total_primary" -gt 1 && "$group_replication_single_primary_mode" == "ON" ]]; then color "警告:单主模式下出现多个 PRIMARY 节点(可能脑裂)!" 1 #return 2 # 返回警告状态码 else color "成功:集群中有 $total_primary 个 PRIMARY 节点" 0 #return 0 # 返回成功状态码 fi color "=====正在检查集群中是否存在 PRIMARY 节点 end =======" 0 } # 检查集群中的 PRIMARY 节点并返回其主机名 check_cluster_primary_node() { color "=====正在检查集群中的 PRIMARY 节点 start ========" 0 PRIMARY_HOST="" local host_count=${#HOSTS[@]} local found=0 # 遍历所有主机,查找 PRIMARY 节点 for host in "${HOSTS[@]}"; do color "正在从主机 $host 查询 PRIMARY 节点..." 0 # 获取当前主机视角的 PRIMARY 节点 local primary_candidate=$(ssh root@"$host" "mysql -u root -p'$MYSQL_PWD' -Ns -e ' SELECT MEMBER_HOST FROM performance_schema.replication_group_members WHERE MEMBER_STATE = \"ONLINE\" AND MEMBER_ROLE = \"PRIMARY\" '") # 验证查询结果有效性 if [[ -n "$primary_candidate" ]]; then if [[ -z "$PRIMARY_HOST" ]]; then PRIMARY_HOST="$primary_candidate" color "发现 PRIMARY 节点: $PRIMARY_HOST" 1 found=1 elif [[ "$primary_candidate" != "$PRIMARY_HOST" ]]; then color "警告: 主机 $host 报告的 PRIMARY 节点($primary_candidate)与之前不一致!" 1 color "可能存在脑裂,请检查网络分区!" 1 fi else color "主机 $host 未发现 ONLINE 状态的 PRIMARY 节点" 0 fi # 短暂延迟,避免并发查询过多 sleep 2 done sleep 2 # 判断最终结果 if [[ $found -eq 0 ]]; then color "错误: 集群中未发现 PRIMARY 节点!" 1 else color "成功: 集群 PRIMARY 节点为 $PRIMARY_HOST" 2 echo "$PRIMARY_HOST" # 输出 PRIMARY 节点主机名 fi color "=====正在检查集群中的 PRIMARY 节点 end ========" 0 } # 显示集群状态摘要 show_cluster_status() { color "=======正在显示集群状态摘要 start =======" 0 for host in "${HOSTS[@]}"; do # 使用 mysqladmin ping 检查连接状态 if ssh root@"$host" "mysqladmin ping -h localhost -uroot -p'$MYSQL_PWD' --silent"; then service_status="active" # 获取节点在集群中的角色和状态 node_info=$(ssh root@"$host" "mysql -u root -p'$MYSQL_PWD' -Ns <<EOF SELECT CONCAT(MEMBER_HOST, ':', MEMBER_STATE, ':', MEMBER_ROLE) FROM performance_schema.replication_group_members WHERE MEMBER_HOST = '$host'; EOF") # 输出结果 if [[ -n "$node_info" ]]; then color "节点 $host: MySQL状态=$service_status, 集群角色=$node_info" 0 fi else service_status="inactive" color "节点 $host: MySQL状态=$service_status, 未加入集群或无法连接" 2 fi sleep 1 done sleep 1 color "=======正在显示集群状态摘要 end =====" 0 } # 启动集群环境 cluster_start_sql(){ color "-------正在启动集群环境 start -----" 0 # 确保至少有一个主机 if [[ ${#HOSTS[@]} -lt 1 ]]; then color "错误: 主机列表为空" 2 return 1 fi # SQL 脚本内容 PRIMARY_SQL=$(cat <<-'EOF' # 主服务器启动时并不会直接启动复制组,通过下面的命令动态的开启复制组是我们的集群更安全 SET GLOBAL group_replication_bootstrap_group=ON; # 开启组网数据同步,该步骤尽在master节点上运行 START GROUP_REPLICATION USER='rpl_user', PASSWORD='123456'; SET GLOBAL group_replication_bootstrap_group=OFF; EOF ) # 执行主节点启动命令 color "$PRIMARY_HOST 主机正在启动集群主角色环境" 0 # 通过 SSH 执行 MySQL 命令 ssh root@$PRIMARY_HOST "mysql -u root -p'$MYSQL_PWD'<<'EOF' $PRIMARY_SQL EOF" # 等待主节点完全启动 sleep 2 # 从节点启动脚本 # SQL 脚本内容 SECONDARY_SQL=$(cat <<-'EOF' # 配置复制源并加入集群 change replication source to source_user='rpl_user',source_password='123456' for channel 'group_replication_recovery'; start group_replication user='rpl_user',password='123456'; EOF ) # 启动其他从节点 for host in "${HOSTS[@]}"; do if [[ "$host" == "$PRIMARY_HOST" ]]; then continue # 跳过主节点 fi color "$host 主机正在启动集群从角色环境" 0 # 通过 SSH 执行 MySQL 命令 ssh root@$host "mysql -u root -p'$MYSQL_PWD'<<'EOF' $SECONDARY_SQL EOF" # 短暂延迟,避免同时启动导致网络压力 sleep 2 done sleep 1 # 检查集群中是否存在 PRIMARY 节点 check_cluster_primary_exists # 检查集群状态信息 check_cluster_online_exists # 检查集群中的 PRIMARY 节点并返回其主机名 check_cluster_primary_node # 显示集群状态摘要 show_cluster_status color "-----正在启动集群环境 end ----" 0 } # 安装msyql环境 install_mysql_server () { # 安装并启动 MySQL 服务 install_mysql_soft # 检查Mysql是否启动 check_mysql_is_active alter_mysql_pwd get_mysql_version mysql_config # 集群认证环境 cluster_auth_init_sql # 启动集群环境 cluster_start_sql # 显示集群状态摘要 show_cluster_status } main(){ # 免密认证 pwd_auth_across_host # 基础环境 base_environment # 安装msyql环境 install_mysql_server } main效果endl
MGR集群auto认证脚本 MGR集群auto认证脚本#!/bin/bash # ************************************* # * 功能: Shell脚本模板 # * 作者: 刘丹玉 # * 联系: v649352141@163.com # * 版本: 2025-05-18 # ************************************* # 错误处理:如果命令执行失败,脚本将终止 set -e # 调试处理 # set -x MYSQL_PWD="Mysql.123456" MYSQL_VERION="8.0.41" MYSQL_PORT="3306" PORT="33061" OS_NAME="Rocky" MY_UUID=$(uuidgen) # 预定义主机列表 #HOSTS=("10.0.0.12" "10.0.0.15" "10.0.0.18") HOSTS=() PRIMARY_HOST="10.0.0.12" # 集群总节点数n ONLINE_COUNT="${#HOSTS[@]}" # 颜色脚本,通用 color () { RES_COL=80 MOVE_TO_COL="echo -en \\033[${RES_COL}G" SETCOLOR_SUCCESS="echo -en \\033[1;32m" SETCOLOR_FAILURE="echo -en \\033[1;31m" SETCOLOR_WARNING="echo -en \\033[1;33m" SETCOLOR_NORMAL="echo -en \E[0m" echo -n "$1" && $MOVE_TO_COL echo -n "[" if [[ $2 = "success" || $2 = "0" ]] ;then ${SETCOLOR_SUCCESS} echo -n $" OK " elif [[ $2 = "failure" || $2 = "1" ]] ;then ${SETCOLOR_FAILURE} echo -n $"FAILED" else ${SETCOLOR_WARNING} echo -n $"WARNING" fi ${SETCOLOR_NORMAL} echo -n "]" echo } # 查看属于Rocky、Ubuntu、openEuler系列 os_type () { $OS_NAME=$(awk -F'[ "]' '/^NAME/{print $2}' /etc/os-release) } # 免密认证 pwd_auth_across_host(){ color "==========免密认证 start============" 0 # 设置本机ip和密码 #read -s -p "请输入本机的密码:" secret read -p "请输入本机的密码:" secret echo # 换行,让后续输出从新行开始 # 检查密码是否为空 if [ -z "$secret" ]; then echo "错误:密码不能为空!" >&2 exit 1 fi # 可选:使用密码进行后续操作 echo "密码已设置,进行后续操作..." echo "清空 ip_up.txt 文件" > ip_up.txt # 生成 SSH 密钥对,不输出信息到屏幕 echo "生成 SSH 密钥对" ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa > /dev/null 2>&1 # 循环读取用户输入 while true;do read -p "请输入主机IP和密码(格式为 ip:password,输入空行结束): " str # 检查是否为空行(用户想结束输入) if [ -z "$str" ]; then break fi # 将输入追加到ip_up.txt echo "$str" >> ip.txt echo "已添加: $str" done # 检查是否添加了任何内容 if [ -s "ip.txt" ]; then echo "已成功将内容保存到 ip.txt" else exit 1 fi echo "判断是否安装expect" ! rpm -q expect &>/dev/null && { echo "未安装 expect,正在尝试安装..."; yum -y install expect &>/dev/null || { echo "错误:expect 安装失败,请检查网络连接或权限" >&2; exit 1; }; } echo "将ssh密钥对复制到本地主机" # 使用 expect 实现 ssh-copy-id 到本地主机 /usr/bin/expect <<-END &>/dev/null spawn ssh-copy-id 127.1 expect { "yes/no" { send "yes\r"; exp_continue } "password:" { send "$secret\r" } timeout { puts "连接 127.0.0.1 超时,推送失败。" exit 1 } eof { if { [exp_status] != 0 } { puts "向 127.0.0.1 推送公钥失败。" exit 1 } } } expect eof END # 循环判断主机是否 ping 通,如果 ping 通则推送秘钥对 while IFS=: read -r ip pass; do # 检查读取的行是否符合格式 if [ -z "$ip" ] || [ -z "$pass" ]; then echo "ip.txt 文件中存在格式错误的行:$ip:$pass" continue fi ping -c1 $ip &>/dev/null if [ $? -eq 0 ];then echo $ip $pass echo $ip $pass >> ip_up.txt /usr/bin/expect <<-END &>/dev/null spawn rsync -avz /root/.ssh/ $ip:/root/.ssh/ expect { "yes/no" { send "yes\r";exp_continue } "password:" { send "$pass\r" } timeout { puts "连接 $ip 超时,推送失败。" exit 1 } eof { if { [regexp -nocase "Permission denied" \$expect_out(buffer)] } { puts "认证失败: $ip" exit 1 } else { puts "密钥推送成功: $ip" exit 0 } } } expect eof END fi done < ip.txt wait echo "秘钥已经推送完毕,正在测试..." echo "测试所有可达主机的公钥推送是否成功" all_success=true while read -r line; do remote_ip=$(echo "$line" | cut -d' ' -f1) ssh root@"$remote_ip" hostname &>/dev/null if [ $? -ne 0 ]; then echo "向 $remote_ip 推送公钥失败。" all_success=false fi done < ip_up.txt # 或从文件读取(确保文件每行一个主机名) HOSTS=() while IFS= read -r line; do # 过滤掉空行 if [[ -n "$line" ]]; then # 提取每行的第一个字段(以空格分隔) host=$(echo "$line" | cut -d' ' -f1) # 正确添加到数组 HOSTS+=("$host") fi done < ip_up.txt echo ${HOSTS[@]} PRIMARY_HOST="${HOSTS[0]}" if $all_success; then echo "秘钥成功推送完毕" else echo "部分主机公钥推送失败,请检查。" fi color "==========免密认证 end============" 0 } # 基础环境 base_environment(){ color "=============== MySQL 基础环境 start ===============" 0 for host in "${HOSTS[@]}"; do # 获取ip最后一位 last_octet=${host##*.} # 获取数组索引(正确方式) for i in "${!HOSTS[@]}"; do if [[ "${HOSTS[$i]}" == "$host" ]]; then index=$i break fi done name="rocky9-$last_octet-mgr0$((index + 1))" # 修改主机名 ssh root@$host "hostnamectl set-hostname $name" # 配置主机名称解析 echo $host $name >> /etc/hosts sleep 1 # 临时关闭SELINUX ssh root@10.0.0.12 ' if grep -q "SELINUX=enforcing" /etc/selinux/config; then setenforce 0 else echo "SELinux 已禁用,无需操作" 0 fi ' # 永久关闭SELINUX ssh root@$host "sed -i.bak 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config" sleep 1 # 临时关闭防火墙 ssh root@$host "systemctl disable --now firewalld && nft flush ruleset" done for host in "${HOSTS[@]}"; do scp /etc/hosts root@$host:/etc/hosts done color "=============== MySQL 基础环境 end ===============" 0 } # 安装并启动 MySQL 服务 install_mysql_soft() { color "=============== 正在安装 MySQL 软件 start ===============" 0 for host in "${HOSTS[@]}"; do # 检查是否已安装 if ! ssh root@"$host" "rpm -q mysql-server";then color "节点 $host 未安装 MySQL,开始安装..." 2 if ssh root@"$host" "yum -y install mysql-server >/dev/null 2>&1";then color "节点 $host MySQL 安装成功!" 0 else color "错误:节点 $host MySQL 安装失败!" 2 fi else color "节点 $host 已安装 MySQL" 0 fi sleep 1 done color "=============== 正在安装 MySQL 软件 end ===============" 3 } # 检查Mysql是否启动 check_mysql_is_active(){ color "=============== 正在测试 MySQL 是否存活 ===============" 0 for host in "${HOSTS[@]}"; do # 检查服务状态 if ! ssh root@"$host" "systemctl is-active mysqld"; then # 尝试重启 if ssh root@"$host" "systemctl restart mysqld && systemctl enable mysqld" >/dev/null 2>&1; then color "节点 $host MySQL 服务已启动并设置为开机自启!" 0 else color "错误:节点 $host MySQL 服务启动失败!" 2 fi fi sleep 1 done sleep 2 color "=============== MySQL 状态检查完成 ===============" 0 } # 正在测试 MySQL 是否存活 check_mysql_status(){ color "=============== 正在测试 MySQL 是否存活 start ============" 0 for host in "${HOSTS[@]}"; do # 使用 mysqladmin ping 检查连接状态 if ssh root@"$host" "mysqladmin ping -h localhost -uroot -p'$MYSQL_PWD' --silent" >/dev/null 2&>1; then color "节点 $host MySQL 服务已运行且可连接" 0 else # 检查Mysql是否启动 check_mysql_is_active color "节点 $host MySQL 无响应,尝试重启..." 1 fi done color "=============== 正在测试 MySQL 是否存活 end ============" 0 } # 修改mysql密码 alter_mysql_pwd() { color "========正在修改mysql密码 start ======" 0 for host in "${HOSTS[@]}"; do color "正在修改主机 $host 的 MySQL 密码..." 0 # 使用当前密码执行 SQL 命令 ssh root@"$host" "mysql -e \"ALTER USER root@'localhost' IDENTIFIED BY '$MYSQL_PWD';\"" color "节点 $host MySQL 服务密码已修改" 0 sleep 1 done sleep 2 color "=========正在修改mysql密码 end ========" 0 # 检查mysql连接状态 check_mysql_status } get_mysql_version() { color "========正在获取mysql版本信息 start =======" 0 # 定义获取版本的 SQL 命令 local SQL_COMMAND="SELECT VERSION();" # 遍历所有主机获取 MySQL 版本 for host in "${HOSTS[@]}"; do color "正在获取主机 $host 的 MySQL 版本..." 0 # 通过 SSH 执行 MySQL 命令并获取版本 local version=$(ssh root@"$host" "mysql -u root -p'$MYSQL_PWD' --batch --skip-column-names <<EOF $SQL_COMMAND EOF") # 检查命令是否成功执行 if [[ $? -ne 0 || -z "$version" ]]; then color "错误:无法获取主机 $host 的 MySQL 版本!" 2 continue fi # 显示版本信息 color "主机 $host 的 MySQL 版本为: $version" 0 # 短暂延迟,避免并发查询过多 sleep 2 done sleep 2 color "=======正在获取mysql版本信息 end ========" 0 } # 配置文件 mysql_config(){ color "=======正在集群配置文件 start =======" 0 # 格式化并拼接 hosts_with_port=$(printf "%s:$PORT,\n" "${HOSTS[@]}" | tr -d '\n' | sed 's/,$//') for host in "${HOSTS[@]}";do color "$host 主机正在写入配置文件" last_octet=$(echo $host | awk -F'.' '{print $4}') ssh root@$host <<- EOF cat > /etc/my.cnf.d/mysql-server.cnf <<- 'eof' [mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock log-error=/var/log/mysql/mysqld.log pid-file=/run/mysqld/mysqld.pid # 为了版本兼容性,更改默认的用户认证插件 default_authentication_plugin=mysql_native_password # 设置MySQL插件目录:MGR基于插件,必须设置插件路径 plugin_dir=/usr/lib64/mysql/plugin # 复制框架 server_id=$last_octet # 开启binlog的GTID模式(MGR强制要求) gtid_mode=ON # 开启后MySQL只允许能够保障事务安全,并且能够被日志记录的SQL语句被执行 enforce_gtid_consistency=ON # 关闭binlog校验(MGR强制要求) binlog_checksum=NONE log_bin=binlog log_slave_updates=ON binlog_format=ROW master_info_repository=TABLE relay_log_info_repository=TABLE # 组复制设置 # server必须为每个事务收集写集合,并使用XXHASH64哈希算法将其编码为散列 transaction_write_set_extraction=XXHASH64 # 启用组复制模块 plugin_load_add='group_replication.so' # 告知插件加入或创建组命名,UUID group_replication_group_name="$MY_UUID" # server启动时不自启组复制,为了避免每次启动自动引导具有相同名称的第二个组,所以设置为OFF。 group_replication_start_on_boot=off # 告诉插件使用IP地址,端口33061用于接收组中其他成员转入连接 # 注意:此处可以使用ip地址,也可以使用主机名方式 group_replication_local_address="$host:$PORT" # 启动组server,种子server,加入组应该连接这些的ip和端口;其他server要加入组得由组成员同意 # 注意:此处可以使用ip地址,也可以使用主机名方式 group_replication_group_seeds="$hosts_with_port" # 配置此服务器为引导组,这个选项必须仅在一台服务器上设置, # 并且仅当第一次启动组或者重新启动整个组时。成功引导组启动后,将此选项设置为关闭。 group_replication_bootstrap_group=off # 指定当前节点向集群其他成员报告的自身的主机名或 IP 地址,用于成员间通信和连接 # 这是保证集群成员间正确通信的基础配置。 report_host=$host report_port=$MYSQL_PORT eof EOF done # 重启MySQL服务 for host in "${HOSTS[@]}"; do ssh root@$host systemctl restart mysqld sleep 1 done sleep 2 color "=======正在集群配置文件 end ========" 0 } # 集群认证环境 cluster_auth_init_sql(){ color "=======正在集群认证环境 start ========" 0 # SQL 脚本内容 SQL_SCRIPT=$(cat <<-'EOF' # 如下操作不记录二进制日志 SET SQL_LOG_BIN=0; # 创建rpl_user账户,此账户用于实现主从数据同步 CREATE USER rpl_user@'%' IDENTIFIED BY '123456'; GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%'; GRANT CONNECTION_ADMIN ON *.* TO rpl_user@'%'; GRANT BACKUP_ADMIN ON *.* TO rpl_user@'%'; GRANT GROUP_REPLICATION_STREAM ON *.* TO rpl_user@'%'; # 创建一个远程连接用户,便于图形化管理工具使用 create user 'remote'@'%' identified with mysql_native_password by '123456'; grant all privileges on *.* to remote@'%'; FLUSH PRIVILEGES; # 恢复二进制日志功能并且重置二进制日志 SET SQL_LOG_BIN=1; RESET MASTER; EOF ) # 循环执行 for host in "${HOSTS[@]}"; do color "$host 主机正在集群认证" 0 # 通过 SSH 执行 MySQL 命令 ssh root@$host "mysql -u root -p'$MYSQL_PWD' <<EOF $SQL_SCRIPT EOF" if [ $? -eq 0 ]; then color "主机 $host 执行集群认证成功!" 0 else color "主机 $host 执行集群认证失败!" 2 fi done color "=======正在集群认证环境 end =======" 0 } # 获取集群的MEMBER_STATE状态信息:OFFLINE离线状态、ONLINE在线状态、RECOVERING恢复状态、UNREACHABLE不可达状态、ERROR错误状态 # 检查集群状态信息 check_cluster_online_exists() { color "=====正在检查集群状态信息 start ======" 0 local total_online=0 local host_count=${#HOSTS[@]} # 循环执行 for host in "${HOSTS[@]}"; do color "正在检查主机 $host 的集群状态..." 0 # 获取当前主机看到的在线节点数 ONLINE_COUNT=$(ssh root@"$host" "mysql -u root -p'$MYSQL_PWD' -Ns -e ' SELECT COUNT(*) FROM performance_schema.replication_group_members WHERE MEMBER_STATE = \"ONLINE\" '") # 验证查询结果是否有效 if [[ -z "$ONLINE_COUNT" || "$ONLINE_COUNT" -lt 0 ]]; then color "错误:无法从主机 $host 获取有效集群状态!" 1 continue fi color "主机 $host 报告:集群中有 $ONLINE_COUNT 个节点在线" 0 # 记录最大在线节点数(避免因网络分区导致部分节点看到不同结果) if [[ "$ONLINE_COUNT" -gt "$total_online" ]]; then total_online="$ONLINE_COUNT" fi sleep 1 done sleep 2 # 判断集群状态 if [[ "$total_online" -eq 0 ]]; then color "错误:集群中没有在线节点,集群处于离线状态!" 2 elif [[ "$total_online" -lt "$host_count" ]]; then color "警告:集群不完整!总节点数: $host_count, 在线节点: $total_online" 2 else color "成功:所有 $total_online 个节点均在线,集群状态正常!" 0 fi color "======正在检查集群状态信息 end =======" 0 } # 检查集群中是否存在 PRIMARY 节点 check_cluster_primary_exists() { color "=====正在检查集群中是否存在 PRIMARY 节点 start =====" 0 local total_primary=0 local host_count=${#HOSTS[@]} # 遍历所有主机,统计 PRIMARY 节点总数 for host in "${HOSTS[@]}"; do color "正在检查主机 $host 的 PRIMARY 节点..." 1 # 获取当前主机视角的 PRIMARY 节点数(单主模式下应为 1) local primary_count=$(ssh root@"$host" "mysql -u root -p'$MYSQL_PWD' -Ns -e ' SELECT COUNT(*) FROM performance_schema.replication_group_members WHERE MEMBER_STATE = \"ONLINE\" AND MEMBER_ROLE = \"PRIMARY\" '") # 验证结果有效性 if [[ -z "$primary_count" || ! "$primary_count" =~ ^[0-9]+$ ]]; then color "错误:主机 $host 返回无效数据!" 2 continue fi color "主机 $host 报告:PRIMARY 节点数 = $primary_count" 1 # 累加 PRIMARY 节点数(正常情况下所有主机的统计应一致) ((total_primary += primary_count)) sleep 1 done sleep 2 # 判断集群 PRIMARY 节点状态 if [[ "$total_primary" -eq 0 ]]; then color "错误:集群中没有 ONLINE 状态的 PRIMARY 节点!" 2 #return 1 # 返回失败状态码 elif [[ "$total_primary" -gt 1 && "$group_replication_single_primary_mode" == "ON" ]]; then color "警告:单主模式下出现多个 PRIMARY 节点(可能脑裂)!" 1 #return 2 # 返回警告状态码 else color "成功:集群中有 $total_primary 个 PRIMARY 节点" 0 #return 0 # 返回成功状态码 fi color "=====正在检查集群中是否存在 PRIMARY 节点 end =======" 0 } # 检查集群中的 PRIMARY 节点并返回其主机名 check_cluster_primary_node() { color "=====正在检查集群中的 PRIMARY 节点 start ========" 0 PRIMARY_HOST="" local host_count=${#HOSTS[@]} local found=0 # 遍历所有主机,查找 PRIMARY 节点 for host in "${HOSTS[@]}"; do color "正在从主机 $host 查询 PRIMARY 节点..." 0 # 获取当前主机视角的 PRIMARY 节点 local primary_candidate=$(ssh root@"$host" "mysql -u root -p'$MYSQL_PWD' -Ns -e ' SELECT MEMBER_HOST FROM performance_schema.replication_group_members WHERE MEMBER_STATE = \"ONLINE\" AND MEMBER_ROLE = \"PRIMARY\" '") # 验证查询结果有效性 if [[ -n "$primary_candidate" ]]; then if [[ -z "$PRIMARY_HOST" ]]; then PRIMARY_HOST="$primary_candidate" color "发现 PRIMARY 节点: $PRIMARY_HOST" 1 found=1 elif [[ "$primary_candidate" != "$PRIMARY_HOST" ]]; then color "警告: 主机 $host 报告的 PRIMARY 节点($primary_candidate)与之前不一致!" 1 color "可能存在脑裂,请检查网络分区!" 1 fi else color "主机 $host 未发现 ONLINE 状态的 PRIMARY 节点" 0 fi # 短暂延迟,避免并发查询过多 sleep 2 done sleep 2 # 判断最终结果 if [[ $found -eq 0 ]]; then color "错误: 集群中未发现 PRIMARY 节点!" 1 else color "成功: 集群 PRIMARY 节点为 $PRIMARY_HOST" 2 echo "$PRIMARY_HOST" # 输出 PRIMARY 节点主机名 fi color "=====正在检查集群中的 PRIMARY 节点 end ========" 0 } # 显示集群状态摘要 show_cluster_status() { color "=======正在显示集群状态摘要 start =======" 0 for host in "${HOSTS[@]}"; do # 使用 mysqladmin ping 检查连接状态 if ssh root@"$host" "mysqladmin ping -h localhost -uroot -p'$MYSQL_PWD' --silent"; then service_status="active" # 获取节点在集群中的角色和状态 node_info=$(ssh root@"$host" "mysql -u root -p'$MYSQL_PWD' -Ns <<EOF SELECT CONCAT(MEMBER_HOST, ':', MEMBER_STATE, ':', MEMBER_ROLE) FROM performance_schema.replication_group_members WHERE MEMBER_HOST = '$host'; EOF") # 输出结果 if [[ -n "$node_info" ]]; then color "节点 $host: MySQL状态=$service_status, 集群角色=$node_info" 0 fi else service_status="inactive" color "节点 $host: MySQL状态=$service_status, 未加入集群或无法连接" 2 fi sleep 1 done sleep 1 color "=======正在显示集群状态摘要 end =====" 0 } # 启动集群环境 cluster_start_sql(){ color "-------正在启动集群环境 start -----" 0 # 确保至少有一个主机 if [[ ${#HOSTS[@]} -lt 1 ]]; then color "错误: 主机列表为空" 2 return 1 fi # SQL 脚本内容 PRIMARY_SQL=$(cat <<-'EOF' # 主服务器启动时并不会直接启动复制组,通过下面的命令动态的开启复制组是我们的集群更安全 SET GLOBAL group_replication_bootstrap_group=ON; # 开启组网数据同步,该步骤尽在master节点上运行 START GROUP_REPLICATION USER='rpl_user', PASSWORD='123456'; SET GLOBAL group_replication_bootstrap_group=OFF; EOF ) # 执行主节点启动命令 color "$PRIMARY_HOST 主机正在启动集群主角色环境" 0 # 通过 SSH 执行 MySQL 命令 ssh root@$PRIMARY_HOST "mysql -u root -p'$MYSQL_PWD'<<'EOF' $PRIMARY_SQL EOF" # 等待主节点完全启动 sleep 2 # 从节点启动脚本 # SQL 脚本内容 SECONDARY_SQL=$(cat <<-'EOF' # 配置复制源并加入集群 change replication source to source_user='rpl_user',source_password='123456' for channel 'group_replication_recovery'; start group_replication user='rpl_user',password='123456'; EOF ) # 启动其他从节点 for host in "${HOSTS[@]}"; do if [[ "$host" == "$PRIMARY_HOST" ]]; then continue # 跳过主节点 fi color "$host 主机正在启动集群从角色环境" 0 # 通过 SSH 执行 MySQL 命令 ssh root@$host "mysql -u root -p'$MYSQL_PWD'<<'EOF' $SECONDARY_SQL EOF" # 短暂延迟,避免同时启动导致网络压力 sleep 2 done sleep 1 # 检查集群中是否存在 PRIMARY 节点 check_cluster_primary_exists # 检查集群状态信息 check_cluster_online_exists # 检查集群中的 PRIMARY 节点并返回其主机名 check_cluster_primary_node # 显示集群状态摘要 show_cluster_status color "-----正在启动集群环境 end ----" 0 } # 安装msyql环境 install_mysql_server () { # 安装并启动 MySQL 服务 install_mysql_soft # 检查Mysql是否启动 check_mysql_is_active alter_mysql_pwd get_mysql_version mysql_config # 集群认证环境 cluster_auth_init_sql # 启动集群环境 cluster_start_sql # 显示集群状态摘要 show_cluster_status } main(){ # 免密认证 pwd_auth_across_host # 基础环境 base_environment # 安装msyql环境 install_mysql_server } main效果endl -
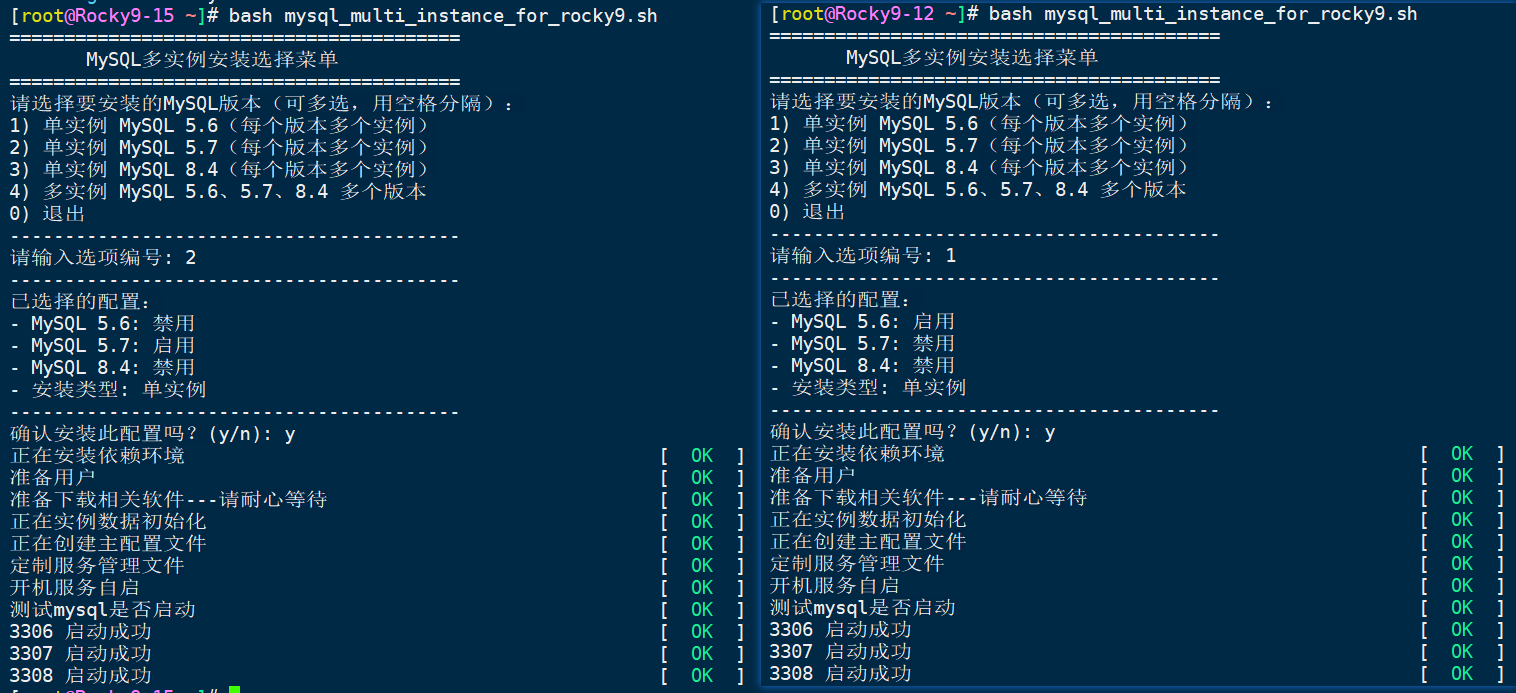
mysql_multi_instance_for_rocky9-mysql多实例脚本 mysql多实例脚本#!/bin/bash # ************************************* # * 功能: Shell脚本模板 # * 作者: 刘丹玉 # * 联系: v649352141@163.com # * 版本: 2025-05-15 # ************************************* # 错误处理:如果命令执行失败,脚本将终止 set -e # 调试处理 # set -x MYSQL_6=mysql-5.6.50-linux-glibc2.12-x86_64 MYSQL_7=mysql-5.7.44-linux-glibc2.12-x86_64 MYSQL_8=mysql-8.4.0-linux-glibc2.28-x86_64 SINGLE_6=false SINGLE_7=false SINGLE_8=false MORE_INSTANCE=false # 颜色脚本,通用 color () { RES_COL=60 MOVE_TO_COL="echo -en \\033[${RES_COL}G" SETCOLOR_SUCCESS="echo -en \\033[1;32m" SETCOLOR_FAILURE="echo -en \\033[1;31m" SETCOLOR_WARNING="echo -en \\033[1;33m" SETCOLOR_NORMAL="echo -en \E[0m" echo -n "$1" && $MOVE_TO_COL echo -n "[" if [ $2 = "success" -o $2 = "0" ] ;then ${SETCOLOR_SUCCESS} echo -n $" OK " elif [ $2 = "failure" -o $2 = "1" ] ;then ${SETCOLOR_FAILURE} echo -n $"FAILED" else ${SETCOLOR_WARNING} echo -n $"WARNING" fi ${SETCOLOR_NORMAL} echo -n "]" echo } # 查看属于Rocky、Ubuntu、openEuler系列 os_type () { awk -F'[ "]' '/^NAME/{print $2}' /etc/os-release } # 安装依赖 install_softs () { color "正在安装依赖环境" 0 if [ "${MORE_INSTANCE}" == "true" ];then yum -y install libaio numactl-libs ncurses-compat-libs perl-Data-Dumper autoconf libaio perl-Sys-Hostname ncurses-compat-libs > /dev/null 2>&1 elif [ "${SINGLE_6}" == "true" ];then yum install -y perl-Data-Dumper autoconf libaio perl-Sys-Hostname ncurses-compat-libs > /dev/null 2>&1 elif [ "${SINGLE_7}" == "true" ];then yum -y install libaio numactl-libs ncurses-compat-libs > /dev/null 2>&1 elif [ "${SINGLE_8}" == "true" ];then yum -y install libaio numactl-libs ncurses-compat-libs > /dev/null 2>&1 else exit 1 fi } # 准备用户 add_user (){ color "准备用户" 0 groupadd -r mysql useradd -r -g mysql -s /sbin/nologin mysql } # 软件环境 prepare_install_package () { color "准备下载相关软件---请耐心等待" 0 mkdir -p /mysql/{3306,3307,3308}/{data,etc,socket,log,bin,pid,share} mkdir -p /data/softs cd /data/softs if [ "${SINGLE_6}" == "true" ];then wget https://downloads.mysql.com/archives/get/p/23/file/${MYSQL_6}.tar.gz > /dev/null 2>&1 [ $? -ne 0 ] && { color "下载 ${MYSQL_6}.tar.gz 文件失败" 1; exit; } tar xf ${MYSQL_6}.tar.gz mv ${MYSQL_6} /usr/local/mysql3306 chown -R mysql:mysql /usr/local/mysql3306 fi if [ "${SINGLE_7}" == "true" ];then wget https://downloads.mysql.com/archives/get/p/23/file/${MYSQL_7}.tar.gz > /dev/null 2>&1 [ $? -ne 0 ] && { color "下载 ${MYSQL_7}.tar.gz 文件失败" 1; exit; } tar xf ${MYSQL_7}.tar.gz mv ${MYSQL_7} /usr/local/mysql3307 chown -R mysql:mysql /usr/local/mysql3307 fi if [ "${SINGLE_8}" == "true" ];then wget https://downloads.mysql.com/archives/get/p/23/file/${MYSQL_8}.tar.xz > /dev/null 2>&1 [ $? -ne 0 ] && { color "下载 ${MYSQL_8}.tar.xz 文件失败" 1; exit; } tar xf ${MYSQL_8}.tar.xz mv ${MYSQL_8} /usr/local/mysql3308 chown -R mysql:mysql /usr/local/mysql3308 fi if [ "${MORE_INSTANCE}" == "true" ];then wget https://downloads.mysql.com/archives/get/p/23/file/${MYSQL_6}.tar.gz > /dev/null 2>&1 [ $? -ne 0 ] && { color "下载 ${MYSQL_6}.tar.gz 文件失败" 1; exit; } tar xf ${MYSQL_6}.tar.gz mv ${MYSQL_6} /usr/local/mysql3306 wget https://downloads.mysql.com/archives/get/p/23/file/${MYSQL_7}.tar.gz > /dev/null 2>&1 [ $? -ne 0 ] && { color "下载 ${MYSQL_7}.tar.gz 文件失败" 1; exit; } tar xf ${MYSQL_7}.tar.gz mv ${MYSQL_7} /usr/local/mysql3307 wget https://downloads.mysql.com/archives/get/p/23/file/${MYSQL_8}.tar.xz > /dev/null 2>&1 [ $? -ne 0 ] && { color "下载 ${MYSQL_8}.tar.xz 文件失败" 1; exit; } tar xf ${MYSQL_8}.tar.xz mv ${MYSQL_8} /usr/local/mysql3308 chown -R mysql:mysql /usr/local/mysql3306 chown -R mysql:mysql /usr/local/mysql3307 chown -R mysql:mysql /usr/local/mysql3308 fi chown -R mysql:mysql /mysql/ } # 生成三个实例的初始数据 initialize_data_6(){ if [ "${MORE_INSTANCE}" == "true" ];then echo 'PATH=/usr/local/mysql3306/bin:$PATH' > /etc/profile.d/mysql3306.sh source /etc/profile.d/mysql3306.sh /usr/local/mysql3306/scripts/mysql_install_db --basedir=/usr/local/mysql3306 --datadir=/mysql/3306/data > /dev/null 2>&1 PATH="/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin" elif [ "${SINGLE_6}" == "true" ];then echo 'PATH=/usr/local/mysql3306/bin:$PATH' > /etc/profile.d/mysql3306.sh source /etc/profile.d/mysql3306.sh for i in 6 7 8 do /usr/local/mysql3306/scripts/mysql_install_db --basedir=/usr/local/mysql3306 --datadir=/mysql/330$i/data > /dev/null 2>&1 done else printf "" fi } initialize_data_7(){ if [ "${MORE_INSTANCE}" == "true" ];then echo 'PATH=/usr/local/mysql3307/bin:$PATH' > /etc/profile.d/mysql3307.sh source /etc/profile.d/mysql3307.sh /usr/local/mysql3307/bin/mysqld --initialize-insecure --basedir=/usr/local/mysql3307 --datadir=/mysql/3307/data > /dev/null 2>&1 PATH="/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin" elif [ "${SINGLE_7}" == "true" ];then echo 'PATH=/usr/local/mysql3307/bin:$PATH' > /etc/profile.d/mysql3307.sh source /etc/profile.d/mysql3307.sh for i in 6 7 8 do /usr/local/mysql3307/bin/mysqld --initialize-insecure --basedir=/usr/local/mysql3307 --datadir=/mysql/330$i/data > /dev/null 2>&1 done else printf "" fi } initialize_data_8(){ if [ "${MORE_INSTANCE}" == "true" ];then echo 'PATH=/usr/local/mysql3308/bin:$PATH' > /etc/profile.d/mysql3308.sh source /etc/profile.d/mysql3308.sh /usr/local/mysql3308/bin/mysqld --initialize-insecure --basedir=/usr/local/mysql3308 --datadir=/mysql/3308/data > /dev/null 2>&1 PATH="/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin" elif [ "${SINGLE_8}" == "true" ];then echo 'PATH=/usr/local/mysql3308/bin:$PATH' > /etc/profile.d/mysql3308.sh source /etc/profile.d/mysql3308.sh for i in 6 7 8 do /usr/local/mysql3308/bin/mysqld --initialize-insecure --basedir=/usr/local/mysql3308 --datadir=/mysql/330$i/data > /dev/null 2>&1 done else printf "" fi } # 创建主配置文件 configuration_file_6 (){ if [ "${MORE_INSTANCE}" == "true" ];then cat > /mysql/3306/etc/my.cnf <<-eof [mysqld] port=3306 user=mysql socket = /mysql/3306/socket/mysql.sock basedir = /usr/local/mysql3306 datadir = /mysql/3306/data innodb_file_per_table=on skip_name_resolve = on symbolic-links=0 [client] socket = /mysql/3306/socket/mysql.sock [mysqld_safe] pid-file = /mysql/3306/pid/mysqld.pid log-error = /mysql/3306/log/error.log eof elif [ "${SINGLE_6}" == "true" ];then for i in 6 7 8 do cat > /mysql/330$i/etc/my.cnf <<-eof [mysqld] port=330$i user=mysql socket = /mysql/330$i/socket/mysql.sock basedir = /usr/local/mysql3306 datadir = /mysql/330$i/data innodb_file_per_table=on skip_name_resolve = on symbolic-links=0 [client] socket = /mysql/330$i/socket/mysql.sock [mysqld_safe] pid-file = /mysql/330$i/pid/mysqld.pid log-error = /mysql/330$i/log/error.log eof done else printf "" fi } configuration_file_7 (){ if [ "${MORE_INSTANCE}" == "true" ];then cat > /mysql/3307/etc/my.cnf <<-eof [mysqld] user=mysql port=3307 socket = /mysql/3307/socket/mysql.sock basedir = /usr/local/mysql3307 datadir = /mysql/3307/data skip_name_resolve = 1 pid-file = /mysql/3307/pid/mysqld.pid log-error = /mysql/3307/log/error.log lc-messages-dir = /usr/local/mysql3307/share/english lc-messages = en_US [client] socket = /mysql/3307/socket/mysql.sock eof elif [ "${SINGLE_7}" == "true" ];then for i in 6 7 8 do cat > /mysql/330$i/etc/my.cnf <<-eof [mysqld] user=mysql port=330$i socket = /mysql/330$i/socket/mysql.sock basedir = /usr/local/mysql3307 datadir = /mysql/330$i/data skip_name_resolve = 1 pid-file = /mysql/330$i/pid/mysqld.pid log-error = /mysql/330$i/log/error.log lc-messages-dir = /usr/local/mysql330$i/share/english lc-messages = en_US [client] socket = /mysql/330$i/socket/mysql.sock eof done else printf "" fi } configuration_file_8 (){ if [ "${MORE_INSTANCE}" == "true" ];then cat > /mysql/3308/etc/my.cnf <<-eof [mysql] port = 3308 socket = /mysql/3308/socket/mysql.sock [mysqld] port = 3308 mysqlx_port = 33080 mysqlx_socket = /mysql/3308/socket/mysqlx.sock basedir = /usr/local/mysql3308 datadir = /mysql/3308/data socket = /mysql/3308/socket/mysql.sock pid-file = /mysql/3308/pid/mysqld.pid log-error = /mysql/3308/log/error.log eof elif [ "${SINGLE_8}" == "true" ];then for i in 6 7 8 do cat > /mysql/330$i/etc/my.cnf <<-eof [mysql] port = 330$i socket = /mysql/330$i/socket/mysql.sock [mysqld] port = 330$i mysqlx_port = 330$i0 mysqlx_socket = /mysql/330$i/socket/mysqlx.sock basedir = /usr/local/mysql3308 datadir = /mysql/330$i/data socket = /mysql/330$i/socket/mysql.sock pid-file = /mysql/330$i/pid/mysqld.pid log-error = /mysql/330$i/log/error.log eof done else printf "" fi } # 定制服务管理文件 systemctl_mysql(){ color "定制服务管理文件" 0 if [ "${MORE_INSTANCE}" == "true" ];then for i in 6 7 8 do cat >/usr/lib/systemd/system/mysqld330$i.service<<EOF [Unit] Description=MySQL Community Server Documentation=https://dev.mysql.com/doc/refman/8.4/en/using-systemd.html After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql330$i/bin/mysqld --defaults-file=/mysql/330$i/etc/my.cnf ExecReload=/bin/kill -s HUP \$MAINPID ExecStop=/bin/kill -s TERM \$MAINPID LimitNOFILE = 10000 EOF done elif [ "${SINGLE_6}" == "true" ];then for i in 6 7 8 do cat >/usr/lib/systemd/system/mysqld330$i.service<<EOF [Unit] Description=MySQL Community Server Documentation=https://dev.mysql.com/doc/refman/8.4/en/using-systemd.html After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql3306/bin/mysqld --defaults-file=/mysql/330$i/etc/my.cnf ExecReload=/bin/kill -s HUP \$MAINPID ExecStop=/bin/kill -s TERM \$MAINPID LimitNOFILE = 10000 EOF done elif [ "${SINGLE_7}" == "true" ];then for i in 6 7 8 do cat >/usr/lib/systemd/system/mysqld330$i.service<<EOF [Unit] Description=MySQL Community Server Documentation=https://dev.mysql.com/doc/refman/8.4/en/using-systemd.html After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql3307/bin/mysqld --defaults-file=/mysql/330$i/etc/my.cnf ExecReload=/bin/kill -s HUP \$MAINPID ExecStop=/bin/kill -s TERM \$MAINPID LimitNOFILE = 10000 EOF done elif [ "${SINGLE_8}" == "true" ];then for i in 6 7 8 do cat >/usr/lib/systemd/system/mysqld330$i.service<<EOF [Unit] Description=MySQL Community Server Documentation=https://dev.mysql.com/doc/refman/8.4/en/using-systemd.html After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql3308/bin/mysqld --defaults-file=/mysql/330$i/etc/my.cnf ExecReload=/bin/kill -s HUP \$MAINPID ExecStop=/bin/kill -s TERM \$MAINPID LimitNOFILE = 10000 EOF done else exit 1 fi } # 启动服务 start_mysql(){ color "开机服务自启" 0 # 重载配置 systemctl daemon-reload for i in 6 7 8 do systemctl enable --now mysqld330$i > /dev/null 2>&1 done } # 测试是否存活 test_success(){ color "测试mysql是否启动" 0 if [ "${MORE_INSTANCE}" == "true" ];then for i in 6 7 8 do systemctl status mysqld330$i | grep active > /dev/null 2>&1 if [ $? -eq 0 ];then color "330$i 启动成功" 0 else color "330$i 启动失败" 2 fi done elif [ "${SINGLE_6}" == "true" ];then for i in 6 7 8 do systemctl status mysqld330$i | grep active > /dev/null 2>&1 if [ $? -eq 0 ];then color "330$i 启动成功" 0 else color "330$i 启动失败" 2 fi done elif [ "${SINGLE_7}" == "true" ];then for i in 6 7 8 do systemctl status mysqld330$i | grep active > /dev/null 2>&1 if [ $? -eq 0 ];then color "330$i 启动成功" 0 else color "330$i 启动失败" 2 fi done elif [ "${SINGLE_8}" == "true" ];then for i in 6 7 8 do systemctl status mysqld330$i | grep active > /dev/null 2>&1 if [ $? -eq 0 ];then color "330$i 启动成功" 0 else color "330$i 启动失败" 2 fi done else exit 1 fi } install_mysql (){ # 安装依赖 install_softs # 准备用户 add_user # 软件环境 prepare_install_package # 生成三个实例的初始数据 chown -R mysql:mysql /mysql/ color "正在实例数据初始化" 0 initialize_data_6 initialize_data_7 initialize_data_8 chown -R mysql:mysql /mysql/ # 创建主配置文件 color "正在创建主配置文件" 0 configuration_file_6 configuration_file_7 configuration_file_8 # 定制服务管理文件 systemctl_mysql # 启动服务 start_mysql # 测试是否存活 test_success } # 用户选择函数 select_mysql_version() { echo "=========================================" echo " MySQL多实例安装选择菜单" echo "=========================================" echo "请选择要安装的MySQL版本(可多选,用空格分隔):" echo "1) 单实例 MySQL 5.6(每个版本多个实例)" echo "2) 单实例 MySQL 5.7(每个版本多个实例)" echo "3) 单实例 MySQL 8.4(每个版本多个实例)" echo "4) 多实例 MySQL 5.6、5.7、8.4 多个版本 " echo "0) 退出" echo "-----------------------------------------" read -p "请输入选项编号: " choices # 重置选择变量 SINGLE_6=false SINGLE_7=false SINGLE_8=false MORE_INSTANCE=false for choice in $choices; do case $choice in 1) SINGLE_6=true ;; 2) SINGLE_7=true ;; 3) SINGLE_8=true ;; 4) MORE_INSTANCE=true;; 0) echo "已取消安装,退出脚本。" exit 0 ;; *) echo "无效选项: $choice" select_mysql_version # 递归重新选择 return ;; esac done # 显示选择结果 echo "-----------------------------------------" echo "已选择的配置:" [ "$SINGLE_6" = "true" ] && echo "- MySQL 5.6: 启用" || echo "- MySQL 5.6: 禁用" [ "$SINGLE_7" = "true" ] && echo "- MySQL 5.7: 启用" || echo "- MySQL 5.7: 禁用" [ "$SINGLE_8" = "true" ] && echo "- MySQL 8.4: 启用" || echo "- MySQL 8.4: 禁用" [ "$MORE_INSTANCE" = "true" ] && echo "- 安装类型: 多实例" || echo "- 安装类型: 单实例" echo "-----------------------------------------" read -p "确认安装此配置吗?(y/n): " confirm if [ "$confirm" != "y" ] && [ "$confirm" != "Y" ]; then echo "已取消安装,退出脚本。" exit 0 elif [ $(os_type) == "Rocky" ];then install_mysql else color "不支持 $os_type " 2 fi } select_mysql_versionendl
-
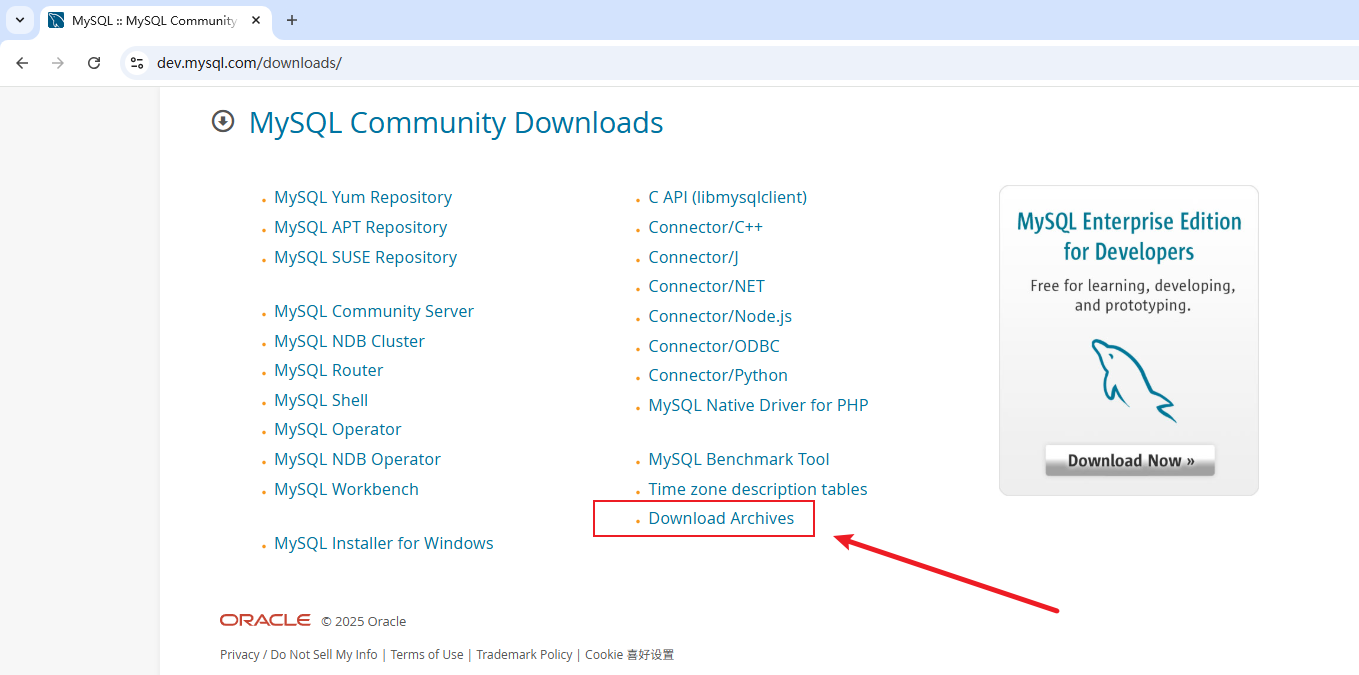
mysql多实例安装 1.mysql5.7.44多实例【rocky9.4】1.1.基础环境安装依赖 yum -y install libaio numactl-libs ncurses-compat-libs1.2.准备用户groupadd -r mysql useradd -r -g mysql -s /sbin/nologin mysql1.3.准备安装包此方法为二进制安装,需要提前下载二进制包直接下载安装包,点击download 右击复制链接地址 https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz1.4.软件环境mkdir -p /data/softs cd /data/softs # 上传下载的安装包到/data/softs目录下 # 也可以使用wget wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz # 解压移动 tar xf mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz mv mysql-5.7.44-linux-glibc2.12-x86_64 /usr/local/mysql1.5.环境变量设定echo 'PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh source /etc/profile.d/mysql.sh1.6.相关目录结构设置# 创建目录 mkdir -pv /mysql/{3306,3307,3308}/{data,etc,socket,log,bin,pid,share}[root@Rocky9-15 ~]# tree /mysql /mysql ├── 3306 │ ├── bin │ ├── data │ ├── etc │ ├── log │ ├── pid │ └── socket │ └── share ├── 3307 │ ├── bin │ ├── data │ ├── etc │ ├── log │ ├── pid │ └── socket │ └── share └── 3308 ├── bin ├── data ├── etc ├── log ├── pid └── socket └── share 24 directories, 0 files# 为目录赋予用户权限 chown -R mysql:mysql /usr/local/mysql/ chown -R mysql:mysql /mysql/1.7.生成三个实例的初始数据# 空密码初始化 for i in 6 7 8 do /usr/local/mysql/bin/mysqld --initialize-insecure --user=mysql --datadir=/mysql/330$i/data done1.8.创建主配置文件for i in 6 7 8 do cat > /mysql/330$i/etc/my.cnf <<-eof [mysqld] user=mysql port=330$i socket = /mysql/330$i/socket/mysql.sock basedir = /mysql/330$i datadir = /mysql/330$i/data skip_name_resolve = 1 pid-file = /mysql/330$i/pid/mysqld.pid log-error = /mysql/330$i/log/error.log lc-messages-dir = /usr/local/mysql/share/english lc-messages = en_US [client] socket = /mysql/330$i/socket/mysql.sock eof done1.9.定制服务管理文件下面两个服务脚本都可以使用服务脚本一for i in 6 7 8 do cat >/usr/lib/systemd/system/mysqld330$i.service<<EOF [Unit] Description=MySQL Community Server Documentation=https://dev.mysql.com/doc/refman/8.4/en/using-systemd.html After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/mysql/330$i/etc/my.cnf ExecReload=/bin/kill -s HUP \$MAINPID ExecStop=/bin/kill -s TERM \$MAINPID LimitNOFILE = 10000 EOF done服务脚本二for i in 6 7 8 do cat >/usr/lib/systemd/system/mysqld330$i.service<<EOF [Unit] Description=MySQL Community Server Documentation=https://dev.mysql.com/doc/refman/8.4/en/using-systemd.html After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/mysql/330$i/etc/my.cnf ExecStop=/usr/local/mysql/bin/mysqladmin -uroot -p'Mysql.123456' -S /mysql/330$i/socket/mysql.sock LimitNOFILE = 10000 EOF done1.10.更改文件属性# 为目录赋予用户权限 chown -R mysql:mysql /mysql/1.11.启动服务# 重载配置 systemctl daemon-reloadfor i in 6 7 8 do systemctl enable --now mysqld330$i done1.12.登录数据库[root@Rocky9-15 ~]# mysql -S /mysql/3306/socket/mysql.sock Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.44 MySQL Community Server (GPL) Copyright (c) 2000, 2023, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> select version(); +-----------+ | version() | +-----------+ | 5.7.44 | +-----------+ 1 row in set (0.00 sec) mysql> exit Bye[root@Rocky9-15 ~]# mysql -S /mysql/3307/socket/mysql.sock -e "select version();" +-----------+ | version() | +-----------+ | 5.7.44 | +-----------+ [root@Rocky9-15 ~]# mysql -S /mysql/3308/socket/mysql.sock -e "select version();" +-----------+ | version() | +-----------+ | 5.7.44 | +-----------+1.13.设置登录密码# 更改密码 for i in 6 7 8 do mysqladmin -uroot -S /mysql/330$i/socket/mysql.sock password 'Mysql.123456' done# 查看版本信息 for i in 6 7 8 do mysql -S /mysql/330$i/socket/mysql.sock -p'Mysql.123456' -e "select version();" done# 查看端口号 for i in 6 7 8 do mysql -S /mysql/330$i/socket/mysql.sock -p'Mysql.123456' -e "select @@port;" done2.mysql8.4.0多实例【rocky9.4】2.1.基础环境# 安装依赖 yum -y install libaio numactl-libs ncurses-compat-libs2.2.准备用户groupadd -r mysql useradd -r -g mysql -s /sbin/nologin mysql2.3.准备安装包mkdir -p /data/softs cd /data/softs wget https://downloads.mysql.com/archives/get/p/23/file/mysql-8.4.0-linux-glibc2.28-x86_64.tar.xz2.4.软件环境cd /data/softs tar xf mysql-8.4.0-linux-glibc2.28-x86_64.tar.xz mv mysql-8.4.0-linux-glibc2.28-x86_64 /usr/local/mysql2.5.环境变量echo 'PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh source /etc/profile.d/mysql.sh2.6.相关目录结构设置mkdir -pv /mysql/{3306,3307,3308}/{data,etc,socket,log,bin,pid,share}[root@Rocky9-15 ~]# tree /mysql/ /mysql/ ├── 3306 │ ├── bin │ ├── data │ ├── etc │ ├── log │ ├── pid │ ├── share │ └── socket ├── 3307 │ ├── bin │ ├── data │ ├── etc │ ├── log │ ├── pid │ ├── share │ └── socket └── 3308 ├── bin ├── data ├── etc ├── log ├── pid ├── share └── socket 24 directories, 0 files# 为目录赋予用户权限 chown -R mysql:mysql /usr/local/mysql/ chown -R mysql:mysql /mysql/2.7.生成三个实例的初始数据# 空密码初始化 for i in 6 7 8 do /usr/local/mysql/bin/mysqld --initialize-insecure --user=mysql --datadir=/mysql/330$i/data done2.8.创建主配置文件for i in 6 7 8 do cat > /mysql/330$i/etc/my.cnf <<-eof [mysql] port = 330$i socket = /mysql/330$i/socket/mysql.sock [mysqld] port = 330$i mysqlx_port = 330$i0 mysqlx_socket = /mysql/330$i/socket/mysqlx.sock basedir = /mysql/330$i datadir = /mysql/330$i/data socket = /mysql/330$i/socket/mysql.sock pid-file = /mysql/330$i/pid/mysqld.pid log-error = /mysql/330$i/log/error.log eof done2.9.定制服务管理文件for i in 6 7 8 do cat >/usr/lib/systemd/system/mysqld330$i.service<<EOF [Unit] Description=MySQL Community Server Documentation=https://dev.mysql.com/doc/refman/8.4/en/using-systemd.html After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/mysql/330$i/etc/my.cnf ExecReload=/bin/kill -s HUP \$MAINPID ExecStop=/bin/kill -s TERM \$MAINPID LimitNOFILE = 10000 EOF done2.10.更改文件属性# 为目录赋予用户权限 chown -R mysql:mysql /mysql/2.11.启动服务# 重载配置 systemctl daemon-reloadfor i in 6 7 8 do systemctl enable --now mysqld330$i done2.12.登录数据库[root@Rocky9-15 ~]# mysql -S /mysql/3306/socket/mysql.sock Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 9 Server version: 8.4.0 MySQL Community Server - GPL Copyright (c) 2000, 2024, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> select version(); +-----------+ | version() | +-----------+ | 8.4.0 | +-----------+ 1 row in set (0.00 sec) mysql> exit Bye[root@Rocky9-15 ~]# mysql -S /mysql/3307/socket/mysql.sock -e "select version();" +-----------+ | version() | +-----------+ | 8.4.0 | +-----------+ [root@Rocky9-15 ~]# mysql -S /mysql/3308/socket/mysql.sock -e "select version();" +-----------+ | version() | +-----------+ | 8.4.0 | +-----------+2.13.设置登录密码# 设置密码 for i in 6 7 8 do mysqladmin -uroot -S /mysql/330$i/socket/mysql.sock password 'Mysql.123456' done# 查看版本信息 for i in 6 7 8 do mysql -S /mysql/330$i/socket/mysql.sock -p'Mysql.123456' -e "select version();" done# 查看端口号 for i in 6 7 8 do mysql -S /mysql/330$i/socket/mysql.sock -p'Mysql.123456' -e "select @@port;" done3.mysql5.6.50多实例【rocky9.4】3.1.基础环境yum install -y perl-Data-Dumper autoconf libaio perl-Sys-Hostname ncurses-compat-libs3.2.准备用户groupadd -r mysql useradd -r -g mysql -s /sbin/nologin mysql3.3.准备安装包mkdir -p /data/softs cd /data/softs wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.6.50-linux-glibc2.12-x86_64.tar.gz3.4.软件环境cd /data/softs tar xf mysql-5.6.50-linux-glibc2.12-x86_64.tar.gz mv mysql-5.6.50-linux-glibc2.12-x86_64 /usr/local/mysql3.5.环境变量echo 'PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh source /etc/profile.d/mysql.sh3.6.相关目录结构设置mkdir -pv /mysql/{3306,3307,3308}/{data,etc,socket,log,bin,pid,share}[root@Rocky9-18 softs]# tree /mysql/ /mysql/ ├── 3306 │ ├── bin │ ├── data │ ├── etc │ ├── log │ ├── pid │ ├── share │ └── socket ├── 3307 │ ├── bin │ ├── data │ ├── etc │ ├── log │ ├── pid │ ├── share │ └── socket └── 3308 ├── bin ├── data ├── etc ├── log ├── pid ├── share └── socket 24 directories, 0 files# 为目录赋予用户权限 chown -R mysql:mysql /usr/local/mysql/ chown -R mysql:mysql /mysql/3.7.生成三个实例的初始数据# 空密码初始化 for i in 6 7 8 do /usr/local/mysql/scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/mysql/330$i/data done3.8.创建主配置文件for i in 6 7 8 do cat > /mysql/330$i/etc/my.cnf <<-eof [mysqld] port=330$i user=mysql socket = /mysql/330$i/socket/mysql.sock basedir = /usr/local/mysql datadir = /mysql/330$i/data innodb_file_per_table=on skip_name_resolve = on symbolic-links=0 [client] socket = /mysql/330$i/socket/mysql.sock [mysqld_safe] pid-file = /mysql/330$i/pid/mysqld.pid log-error = /mysql/330$i/log/error.log eof done3.9.定制服务管理文件for i in 6 7 8 do cat >/usr/lib/systemd/system/mysqld330$i.service<<EOF [Unit] Description=MySQL Community Server Documentation=https://dev.mysql.com/doc/refman/8.4/en/using-systemd.html After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/mysql/330$i/etc/my.cnf ExecReload=/bin/kill -s HUP \$MAINPID ExecStop=/bin/kill -s TERM \$MAINPID LimitNOFILE = 10000 EOF done3.10.更改文件属性# 为目录赋予用户权限 chown -R mysql:mysql /mysql/3.11.启动服务# 重载配置 systemctl daemon-reloadfor i in 6 7 8 do systemctl enable --now mysqld330$i done3.12.登录数据库[root@Rocky9-18 ~]# mysql -S /mysql/3306/socket/mysql.sock Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 Server version: 5.6.50 MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> select version(); +-----------+ | version() | +-----------+ | 5.6.50 | +-----------+ 1 row in set (0.00 sec) mysql> exit Bye3.13.设置登录密码# 设置密码 for i in 6 7 8 do mysqladmin -uroot -S /mysql/330$i/socket/mysql.sock password 'Mysql.123456' done# 查看版本信息 for i in 6 7 8 do mysql -S /mysql/330$i/socket/mysql.sock -p'Mysql.123456' -e "select version();" done# 查看端口号 for i in 6 7 8 do mysql -S /mysql/330$i/socket/mysql.sock -p'Mysql.123456' -e "select @@port;" done4.不同版本(5.6、5.7、8.0)的数据库服务多实例配置实现4.1.多实例部署环境规划实例信息编号实例服务端口实例存储路径实例配置文件套接字文件mysql5.6.503306/mysql/3306/data/mysql/3306/etc/my.cnf/mysql/3306/socket/mysql.sockmysql5.7.443307/mysql/3307/data/mysql/3307/etc/my.cnf/mysql/3307/socket/mysql.sockmysql8.4.03308/mysql/3308/data/mysql/3308/etc/my.cnf/mysql/3308/socket/mysql.sock4.2.基础环境# 安装依赖 yum -y install libaio numactl-libs ncurses-compat-libs perl-Data-Dumper autoconf libaio perl-Sys-Hostname ncurses-compat-libs4.3.准备用户groupadd -r mysql useradd -r -g mysql -s /sbin/nologin mysql4.4.准备安装包mkdir -p /data/softs cd /data/softs wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.6.50-linux-glibc2.12-x86_64.tar.gz wget https://downloads.mysql.com/archives/get/p/23/file/mysql-8.4.0-linux-glibc2.28-x86_64.tar.xz wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz4.5.软件环境如果不想浪费下载时间,可以上传下载好的安装包cd /data/softs tar xf mysql-5.6.50-linux-glibc2.12-x86_64.tar.gz mv mysql-5.6.50-linux-glibc2.12-x86_64 /usr/local/mysql3306 tar xf mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz mv mysql-5.7.44-linux-glibc2.12-x86_64 /usr/local/mysql3307 tar xf mysql-8.4.0-linux-glibc2.28-x86_64.tar.xz mv mysql-8.4.0-linux-glibc2.28-x86_64 /usr/local/mysql33084.6.相关目录结构设置mkdir -pv /mysql/{3306,3307,3308}/{data,etc,socket,log,bin,pid,share}# 为目录赋予用户权限 chown -R mysql:mysql /usr/local/mysql* chown -R mysql:mysql /mysql/4.7.生成三个实例的初始数据由于每个实例初始化都要找环境变量,为了避免冲突 1.配置环境变量 2.初始化mysql脚本 3.初始化环境变量下面最好一个步骤一个步骤执行echo $PATH echo 'PATH=/usr/local/mysql3306/bin:$PATH' > /etc/profile.d/mysql3306.sh source /etc/profile.d/mysql3306.sh /usr/local/mysql3306/scripts/mysql_install_db --basedir=/usr/local/mysql3306 --datadir=/mysql/3306/data PATH="/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin" echo 'PATH=/usr/local/mysql3307/bin:$PATH' > /etc/profile.d/mysql3307.sh source /etc/profile.d/mysql3307.sh /usr/local/mysql3307/bin/mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql3307 --datadir=/mysql/3307/data PATH="/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin" echo 'PATH=/usr/local/mysql3308/bin:$PATH' > /etc/profile.d/mysql3308.sh source /etc/profile.d/mysql3308.sh /usr/local/mysql3308/bin/mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql3308 --datadir=/mysql/3308/data PATH="/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin"4.8.环境变量--可省略注意:环境变量仅对当前窗口有效,如果更换窗口,需要重新执行环境变量echo 'PATH=/usr/local/mysql3306/bin:$PATH' > /etc/profile.d/mysql3306.sh source /etc/profile.d/mysql3306.sh echo 'PATH=/usr/local/mysql3307/bin:$PATH' > /etc/profile.d/mysql3307.sh source /etc/profile.d/mysql3307.sh echo 'PATH=/usr/local/mysql3308/bin:$PATH' > /etc/profile.d/mysql3308.sh source /etc/profile.d/mysql3308.sh4.9.创建主配置文件cat > /mysql/3306/etc/my.cnf <<-eof [mysqld] port=3306 user=mysql socket = /mysql/3306/socket/mysql.sock basedir = /usr/local/mysql3306 datadir = /mysql/3306/data innodb_file_per_table=on skip_name_resolve = on symbolic-links=0 [client] socket = /mysql/3306/socket/mysql.sock [mysqld_safe] pid-file = /mysql/3306/pid/mysqld.pid log-error = /mysql/3306/log/error.log eofcat > /mysql/3307/etc/my.cnf <<-eof [mysqld] user=mysql port=3307 socket = /mysql/3307/socket/mysql.sock basedir = /mysql/3307 datadir = /mysql/3307/data skip_name_resolve = 1 pid-file = /mysql/3307/pid/mysqld.pid log-error = /mysql/3307/log/error.log lc-messages-dir = /usr/local/mysql3307/share/english lc-messages = en_US [client] socket = /mysql/3307/socket/mysql.sock eofcat > /mysql/3308/etc/my.cnf <<-eof [mysql] port = 3308 socket = /mysql/3308/socket/mysql.sock [mysqld] port = 3308 mysqlx_port = 33080 mysqlx_socket = /mysql/3308/socket/mysqlx.sock basedir = /mysql/3308 datadir = /mysql/3308/data socket = /mysql/3308/socket/mysql.sock pid-file = /mysql/3308/pid/mysqld.pid log-error = /mysql/3308/log/error.log eof4.10.定制服务管理文件for i in 6 7 8 do cat >/usr/lib/systemd/system/mysqld330$i.service<<EOF [Unit] Description=MySQL Community Server Documentation=https://dev.mysql.com/doc/refman/8.4/en/using-systemd.html After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql330$i/bin/mysqld --defaults-file=/mysql/330$i/etc/my.cnf ExecReload=/bin/kill -s HUP \$MAINPID ExecStop=/bin/kill -s TERM \$MAINPID LimitNOFILE = 10000 EOF done4.11.更改文件属性# 为目录赋予用户权限 chown -R mysql:mysql /mysql/4.12.启动服务# 重载配置 systemctl daemon-reloadfor i in 6 7 8 do systemctl enable --now mysqld330$i done4.13.测试是否存活for i in 6 7 8 do /usr/local/mysql330$i/bin/mysqladmin -S /mysql/330$i/socket/mysql.sock ping done4.13.登录数据库注意:由于是多个版本的mysql,设置环境变量会发生冲突 所以,登录mysql使用绝对路径登录/usr/local/mysql3306/bin/mysql -S /mysql/3306/socket/mysql.sock /usr/local/mysql3307/bin/mysql -S /mysql/3307/socket/mysql.sock /usr/local/mysql3307/bin/mysql -S /mysql/3307/socket/mysql.sock4.14.设置登录密码# 设置密码 for i in 6 7 8 do /usr/local/mysql330$i/bin/mysqladmin -uroot -S /mysql/330$i/socket/mysql.sock password 'Mysql.123456' done# 查看版本信息 for i in 6 7 8 do /usr/local/mysql330$i/bin/mysql -S /mysql/330$i/socket/mysql.sock -p'Mysql.123456' -e "select version();" done# 查看端口号 for i in 6 7 8 do /usr/local/mysql330$i/bin/mysql -S /mysql/330$i/socket/mysql.sock -p'Mysql.123456' -e "select @@port;" doneendl
-
数据库基础及安装-1 数据库1.数据库原理1.1.E-R模型E-R图模型的组成是由实体,属性和联系三部份组成。实体:( Entity ) 实体是数据的使用者,代表软件系统中客观存在的生活中的实物,同一类实体构成实体集。 在ER图中,实体用矩形表示。 属性:( Attribute ) 实体中的所有特性称为属性,每个属性描述的是实体的单个特性。在ER图中,属性用椭圆形表示。 联系:( Relationship ) 描述了实体的属性之间的关联规则。在ER图中,联系用菱形表示。实体间的联系有三种类型:一对一联系 ( 1:1 ):例如,一个学号只能分配给一个同学,每个同学都有一个学号,则学号与同学的联系是一对一。 一对多联系 ( 1:n ):例如,一个老师可以教授多门课程,每门课程只能有一个老师教授,则老师与课程的联系是一对多。 多对多联系 ( m:n ):例如,一个同学可以报名多门课程,每门课程下有多个同学,则同学与课程的联系是多对多。1.2.设计数据库的基本原则--三大范式第一范式 1NF (确保每列保持原子性) 第二范式 2NF (确保表中的每列都和主键相关) 第三范式 3NF (确保每列都和主键列直接相关,而不是间接相关)1.3.MySQL执行查询语句执行流程MySQL数据库中的SQL查询语句执行流程1 接收查询语句: 用户通过客户端或编程语言框架里面的驱动模块,经由专门的通信协议,向MySQL服务器发送SQL查询语句。 如果是mysql服务端,这里的通信协议端口是 3306 数据库服务端内部的连接器接收查询请求后,首先到本地的缓存记录中检索信息 如果有信息,则直接返回查询结果 如果没有信息,则将信息直接传递给后端的数据库解析器来进行处理2 词法分析和语法分析: MySQL服务器首先会对接收到的查询语句进行词法分析,将其分解成一系列的词法单元。 接着,进行语法分析,检查这些词法单元是否符合SQL语法规则。如果语法错误,MySQL会立即返回错误信息。3 语义分析: 在语法分析之后,MySQL会进行语义分析,检查查询语句中的表、列、函数等是否存在,以及用户是否有足够的权限执行该查询。 语义分析还会检查查询语句中的数据类型是否匹配,以及是否存在违反数据库完整性的约束。4 查询优化: MySQL的查询优化器会对查询语句进行优化,决定最优的执行查询计划 -- 也就是怎么走会效率更快。 优化过程包括选择最佳的访问路径、索引、连接顺序等,以最小化查询的执行时间和资源消耗。 优化器还会考虑统计信息,如表的行数、索引的分布等,以做出更明智的决策。5 查询执行: 优化后的查询计划被传递给执行器进行执行。执行器根据查询计划访问存储引擎,获取数据。 存储引擎将文件系统里面的数据库文件数据,加载到内存,然后在内存中做一次聚合 然后,临时放到查询缓存中,便于下次遇到相同的查询语句重复过来。 在执行过程中,MySQL可能会使用缓存来加速查询的执行。从MySQL 8.0开始,查询缓存已被移除。6 结果集返回: 执行器将查询结果集返回给客户端。结果集可以包含零行或多行数据,具体取决于查询的内容。 如果查询涉及聚合函数(如SUM、AVG等)或分组操作(如GROUP BY),执行器还会在返回结果之前对这些数据进行相应的处理。7 错误处理和日志记录: 如果在执行过程中遇到任何错误(如权限不足、表不存在等),MySQL会返回相应的错误信息给客户端。 同时,MySQL还会记录查询的执行日志,以便进行性能分析和故障排查。主要区别:MySQL 5.7 及之前版本查询缓存常被使用,但存在一些问题(如命中率低、维护开销大)。 MySQL 8.0 弃用查询缓存,避免相关开销。-- 查询2023年每个城市中,购买了“电子产品”类别商品,且订单总金额大于1000元的客户信息 -- 以及他们对应的订单信息和购买的商品明细 SELECT c.customer_name, c.customer_city, o.order_id, o.order_date, o.total_amount, p.product_name, oi.quantity, oi.unit_price FROM customers c -- 连接orders表,获取客户的订单信息 JOIN orders o ON c.customer_id = o.customer_id -- 连接order_items表,获取订单中的商品明细信息 JOIN order_items oi ON o.order_id = oi.order_id -- 连接products表,获取商品的名称等信息 JOIN products p ON oi.product_id = p.product_id -- 连接categories表,获取商品所属类别信息 JOIN categories cat ON p.category_id = cat.category_id WHERE -- 筛选出2023年的订单 YEAR(o.order_date) = 2023 AND -- 筛选出商品类别为“电子产品”的记录 cat.category_name = '电子产品' AND -- 筛选出订单总金额大于1000元的订单 o.total_amount > 1000 GROUP BY -- 按照客户姓名、城市、订单ID、订单日期、订单总金额、商品名称进行分组 c.customer_name, c.customer_city, o.order_id, o.order_date, o.total_amount, p.product_name ORDER BY -- 按照客户所在城市升序、订单总金额降序排序 c.customer_city ASC, o.total_amount DESC;对于这个大的流程来说,专用协议之后的功能,全部由数据库软件来实现,而我们需要做的是前面的各种sql语句的编写。2.Mysql安装方式mysql主流的四种安装方式安装方式说明包管理器进行安装配置好mysql仓库员,用包管理器进行在线安装二进制包本地安装下载已编译完成的压缩包,展开至特定路径,并经过简单配置后即可使用源码编译安装1下载指定版本源码在本地进行编译安装源码编译安装2下载指定版本源码【已编译完毕生成可执行文件】在本地进行环境初始化即可3.关于软件mysql和mariadb安装文件前后对比注意:两个环境安装不同的mysql和mariadb 配置文件的名称和位置都不一样 但是,配置内容,基本上都是一样。 mysql 是 多线程工作模式MysqlRockyubuntu软件名mysql-servermysql-server服务名mysqld.servicemysql.service入口文件/etc/my.cnf/etc/mysql/my.cnf配置目录/etc/my.cnf.d/etc/mysql/mysql.conf.d服务配置/etc/my.cnf.d/mysql-server.cnf/etc/mysql/mysql.conf.d/mysqld.cnf端口:::3306 :::33060127.0.0.1:3306 127.0.0.1:33060MariadbRockyubuntu软件名mariadb-servermariadb-server服务名mariadb.servicemariadb.service入口文件/etc/my.cnf/etc/mysql/my.cnf配置目录/etc/my.cnf.d/etc/mysql/mariadb.conf.d服务配置/etc/my.cnf.d/mariadb-server.cnf/etc/mysql/mariadb.conf.d/50-server.cnf端口:::3306127.0.0.1:33064.包管理进行安装4.1.光盘镜像Rocky9 系列光盘镜像自带 mysql-server 8.0 和 mariadb-server 10.3挂载镜像 [root@Rocky9-12 ~]# mount /dev/cdrom /opt/ mount: /opt: WARNING: source write-protected, mounted read-only. [root@Rocky9-12 ~]# ls /opt/ AppStream BaseOS EFI images isolinux LICENSE media.repo 查看数据库软件 [root@Rocky9-12 ~]# ls /opt/AppStream/Packages/m/mysql-ser* /opt/AppStream/Packages/m/mysql-server-8.0.36-1.el9_3.x86_64.rpm [root@Rocky9-12 ~]# ls /opt/AppStream/Packages/m/mariadb-server-1* /opt/AppStream/Packages/m/mariadb-server-10.11.6-1.module+el9.4.0+20012+a68bdff7.x86_64.rpm /opt/AppStream/Packages/m/mariadb-server-10.5.22-1.el9_2.x86_64.rpm其他信息:CentOS7 系列光盘镜像自带 mariadb-server 5.5 CentOS6 系列光盘镜像自带 mysql-server 5.1[21:37:13 root@centos7 ~]# mount /dev/cdrom /opt mount: /dev/sr0 is write-protected, mounting read-only [21:37:27 root@centos7 ~]# ls /opt/ CentOS_BuildTag EULA images LiveOS repodata RPM-GPG-KEY-CentOS-Testing-7 EFI GPL isolinux Packages RPM-GPG-KEY-CentOS-7 TRANS.TBL 查看数据库软件 [21:38:19 root@centos7 ~]# ls /opt/Packages/mariadb-server-5.5.68-1.el7.x86_64.rpm /opt/Packages/mariadb-server-5.5.68-1.el7.x86_64.rpm4.2.官方yum源源配置地址mariadb 官方源配置页面https://mariadb.org/download/?t=repo-configmysql 官方源配置页面https://dev.mysql.com/downloads阿里云 mysql 源配置页面https://mirrors.aliyun.com/mysql/阿里云 mariadb 源配置页面https://mirrors.aliyun.com/mariadb/清华 mysql 源配置页面https://mirrors.tuna.tsinghua.edu.cn/mysql/yum/清华 mariadb 源配置页面https://mirrors.tuna.tsinghua.edu.cn/mariadb/yum/[root@Rocky9-12 ~]# yum list "mysql" mysql.x86_64 8.0.41-2.el9_5 [root@Rocky9-12 ~]# yum list "mariadb" mariadb.x86_64 3:10.5.27-1.el9_5 4.3.mariadb源如何获取最新的mariadb软件源,参考mariadb 官方源配置页面,选择版本和系统发行版本 注意:目前版本最新为 11.8 官网:https://mariadb.org/download/4.4.mysql源如何获取最新的mysql软件源,参考mysql官方源配置页面 官网:http://dev.mysql.com/downloads/点击需要使用功能的源类型,然后下载对应的包就可以了 MySQL Community Downloads 即 MySQL 社区版下载General Availability (GA) Releases:意思是 “通用版本发布” 通常指软件经过全面测试、达到稳定状态,可供广大用户在生产环境等正式场景使用的版本,按钮为橙色文字。 Archives:意为 “存档” 这里一般指软件过往旧版本的集合,供有特定需求(如兼容性需求)的用户下载使用,按钮为蓝色文字。apt源中版本最新版本是8.34-1yum源版本最新版本是8.0.4x版本结果显示: 社区版,在 APT 源中,目前主流的是8版本 在其他的下载页面,虽然存在9.1.0版本,但是LTS依然是8版本5.Rocky9中安装mysql8.05.1.软件信息获取mysql软件源 [root@Rocky9-12 ~]# yum list mysql mysql-server mysql.x86_64 8.0.41-2.el9_5 appstream mysql-server.x86_64 8.0.41-2.el9_5 appstream获取mariadb的软件源 [root@Rocky9-15 ~]# yum list mariadb mariadb-server mariadb.x86_64 3:10.5.27-1.el9_5 appstream mariadb-server.x86_64 3:10.5.27-1.el9_5 appstream5.2.安装软件安装 mysql-server,会自动安装客户端包【安装客户端不会安装服务端软件】[root@Rocky9-12 ~]# yum install -y mysql-server服务状态 [root@Rocky9-12 ~]# systemctl status mysqld.service ○ mysqld.service - MySQL 8.0 database server Loaded: loaded (/usr/lib/systemd/system/mysqld.service; disabled; preset: disabled) Active: inactive (dead)启动服务 [root@Rocky9-12 ~]# systemctl enable --now mysqld Created symlink /etc/systemd/system/multi-user.target.wants/mysqld.service → /usr/lib/systemd/system/mysqld.service.再次查看 [root@Rocky9-12 ~]# systemctl status mysqld.service ● mysqld.service - MySQL 8.0 database server Loaded: loaded (/usr/lib/systemd/system/mysqld.service; enabled; preset: disabled) Active: active (running) 5.3.环境查看检测mysql的进程状态多线程模式 [root@Rocky9-12 ~]# pstree | grep mysql |-mysqld---36*[{mysqld}]检测其他信息自动创建的账户 [root@Rocky9-12 ~]# getent passwd mysql mysql:x:27:27:MySQL Server:/var/lib/mysql:/sbin/nologin查看mysql真正的家目录 [root@Rocky9-12 ~]# ll /var/lib/mysql total 91604 -rw-r----- 1 mysql mysql 56 May 7 21:58 auto.cnf -rw-r----- 1 mysql mysql 157 May 7 21:58 binlog.000001 -rw-r----- 1 mysql mysql 16 May 7 21:58 binlog.index -rw------- 1 mysql mysql 1705 May 7 21:58 ca-key.pem -rw-r--r-- 1 mysql mysql 1112 May 7 21:58 ca.pem -rw-r--r-- 1 mysql mysql 1112 May 7 21:58 client-cert.pem -rw------- 1 mysql mysql 1705 May 7 21:58 client-key.pem -rw-r----- 1 mysql mysql 196608 May 7 22:00 '#ib_16384_0.dblwr' -rw-r----- 1 mysql mysql 8585216 May 7 21:58 '#ib_16384_1.dblwr' -rw-r----- 1 mysql mysql 6238 May 7 21:58 ib_buffer_pool -rw-r----- 1 mysql mysql 12582912 May 7 21:58 ibdata1 -rw-r----- 1 mysql mysql 12582912 May 7 21:58 ibtmp1 drwxr-x--- 2 mysql mysql 4096 May 7 21:58 '#innodb_redo' drwxr-x--- 2 mysql mysql 187 May 7 21:58 '#innodb_temp' drwxr-x--- 2 mysql mysql 143 May 7 21:58 mysql -rw-r----- 1 mysql mysql 26214400 May 7 21:58 mysql.ibd srwxrwxrwx 1 mysql mysql 0 May 7 21:58 mysql.sock -rw------- 1 mysql mysql 5 May 7 21:58 mysql.sock.lock -rw-r--r-- 1 mysql mysql 7 May 7 21:58 mysql_upgrade_info srwxrwxrwx 1 mysql mysql 0 May 7 21:58 mysqlx.sock -rw------- 1 mysql mysql 5 May 7 21:58 mysqlx.sock.lock drwxr-x--- 2 mysql mysql 8192 May 7 21:58 performance_schema -rw------- 1 mysql mysql 1705 May 7 21:58 private_key.pem -rw-r--r-- 1 mysql mysql 452 May 7 21:58 public_key.pem -rw-r--r-- 1 mysql mysql 1112 May 7 21:58 server-cert.pem -rw------- 1 mysql mysql 1705 May 7 21:58 server-key.pem drwxr-x--- 2 mysql mysql 28 May 7 21:58 sys -rw-r----- 1 mysql mysql 16777216 May 7 22:00 undo_001 -rw-r----- 1 mysql mysql 16777216 May 7 22:00 undo_002查看数据库的数据文件 [root@Rocky9-12 ~]# ls /var/lib/mysql/mysql general_log_213.sdi general_log.CSM general_log.CSV slow_log_214.sdi slow_log.CSM slow_log.CSV 注意:因为这些文件,不是普通的文件系统,它是数据库专用的文件,只能通过数据库的统一接口到这些文件中,进行数据的查找。查看监听端口,默认3306,33060 是8.0版本中的特性 [root@Rocky9-12 ~]# ss -tnulp | grep mysql tcp LISTEN 0 151 *:3306 *:* users:(("mysqld",pid=2520,fd=24)) tcp LISTEN 0 70 *:33060 *:* users:(("mysqld",pid=2520,fd=21)) 注意:X Protocol 是一种新的通信协议,旨在提供更高效、灵活的数据交互方式,让客户端与服务器通信更顺畅。 在 MySQL 8.0 中,33060 端口是 X Protocol 协议的端口 。5.4.登录测试客户端连接: 默认用户名 root,默认密码为空连接到数据库里面 [root@Rocky9-12 ~]# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 8 Server version: 8.0.41 Source distribution mysql>查看当前数据库的版本信息 mysql> select version(); +-----------+ | version() | +-----------+ | 8.0.41 | +-----------+ 1 row in set (0.00 sec) mysql> exit; # 退出数据库的连接客户端连接: 直接使用用户和密码 [root@Rocky9-12 ~]# mysql -uroot -p -P3306 Enter password: # 因为没有密码,所以这里直接Enter即可 Server version: 8.0.41 Source distribution mysql>mysql> \s # 显示当前 MySQL 服务器会话状态的快捷命令 -------------- mysql Ver 8.0.41 for Linux on x86_64 (Source distribution) Connection id: 9 Current database: Current user: root@localhost SSL: Not in use Current pager: stdout Using outfile: '' Using delimiter: ; Server version: 8.0.41 Source distribution Protocol version: 10 Connection: Localhost via UNIX socket Server characterset: utf8mb4 Db characterset: utf8mb4 Client characterset: utf8mb4 Conn. characterset: utf8mb4 UNIX socket: /var/lib/mysql/mysql.sock Binary data as: Hexadecimal Uptime: 8 min 35 sec Threads: 2 Questions: 8 Slow queries: 0 Opens: 120 Flush tables: 3 Open tables: 36 Queries per second avg: 0.015 --------------6.在Rocky9中安装mariadb6.1.软件安装查看mariadb软件 [root@Rocky9-15 ~]# yum list mariadb mariadb.x86_64 3:10.5.27-1.el9_5 appstream安装软件 -- 会自动安装客户端 [root@Rocky9-15 ~]# yum -y install mariadb-server启动服务 [root@Rocky9-15 ~]# systemctl enable --now mariadb Created symlink /etc/systemd/system/mysql.service → /usr/lib/systemd/system/mariadb.service. Created symlink /etc/systemd/system/mysqld.service → /usr/lib/systemd/system/mariadb.service. Created symlink /etc/systemd/system/multi-user.target.wants/mariadb.service → /usr/lib/systemd/system/mariadb.service.查看状态 [root@Rocky9-15 ~]# systemctl status mariadb ● mariadb.service - MariaDB 10.5 database server Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; preset: disabled) Active: active (running)监听端口 [root@Rocky9-15 ~]# ss -tunlp | grep 3306 tcp LISTEN 0 80 *:3306 *:* users:(("mariadbd",pid=3169,fd=19)) # 服务名字变成了 mariadb 注意: mariadb里面没有33060的端口 MariaDB 的设计初衷是保持与 MySQL 高度兼容,主要继承 MySQL 5.5 及之前版本的特性。 它专注于提供稳定、性能良好且与旧版 MySQL 兼容的数据库服务,面向大多数传统数据库应用场景,这些场景不需 要通过 33060 端口使用 X Protocol。多线程状态 [root@Rocky9-15 ~]# pstree | grep maria |-mariadbd---7*[{mariadbd}]查看家目录文件结构 [root@Rocky9-15 ~]# ll /var/lib/mysql/ total 122920 -rw-rw---- 1 mysql mysql 24576 May 7 22:10 aria_log.00000001 -rw-rw---- 1 mysql mysql 52 May 7 22:10 aria_log_control -rw-rw---- 1 mysql mysql 972 May 7 22:10 ib_buffer_pool -rw-rw---- 1 mysql mysql 12582912 May 7 22:10 ibdata1 -rw-rw---- 1 mysql mysql 100663296 May 7 22:10 ib_logfile0 -rw-rw---- 1 mysql mysql 12582912 May 7 22:10 ibtmp1 -rw-rw---- 1 mysql mysql 0 May 7 22:10 multi-master.info drwx------ 2 mysql mysql 4096 May 7 22:10 mysql srwxrwxrwx 1 mysql mysql 0 May 7 22:10 mysql.sock -rw-rw---- 1 mysql mysql 16 May 7 22:10 mysql_upgrade_info drwx------ 2 mysql mysql 20 May 7 22:10 performance_schema检查客户端连接命令 -- 本质上是 mariadb文件 [root@Rocky9-15 ~]# ll /usr/sbin/mysqld lrwxrwxrwx 1 root root 19 Feb 4 19:21 /usr/sbin/mysqld -> /usr/libexec/mysqld [root@Rocky9-15 ~]# ll /usr/libexec/mysqld lrwxrwxrwx 1 root root 8 Feb 4 19:21 /usr/libexec/mysqld -> mariadbd6.2.连接登录客户端连接 [root@Rocky9-15 ~]# mysql Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 3 Server version: 10.5.27-MariaDB MariaDB Server MariaDB [(none)]> select version(); +-----------------+ | version() | +-----------------+ | 10.5.27-MariaDB | +-----------------+ 1 row in set (0.000 sec) MariaDB [(none)]> exit Bye7.Ubuntu24 安装mysql8.07.1.安装软件安装 mysql-server,会自动安装客户端包【安装客户端不会安装服务端软件】 [root@ubuntu24-13:~]# apt install mysql-server -y再次查看状态信息 [root@ubuntu24-13:~]# systemctl status mysql.service ● mysql.service - MySQL Community Server Loaded: loaded (/usr/lib/systemd/system/mysql.service; enabled; preset: enabled) Active: active (running) 注意:如果是第一次安装mysql-server出现服务启动不起来,而且没有提前做任何的配置,那一般情况下,是本地主机环境已经被历史残留的数据信息破坏了。检测mysql的进程状态多线程模式 [root@ubuntu24-13:~]# pstree | grep mysql |-mysqld---36*[{mysqld}] 自己创建的账户 [root@ubuntu24-13:~]# getent passwd mysql mysql:x:110:110:MySQL Server,,,:/nonexistent:/bin/false查看mysql真正的家目录 [root@ubuntu24-13:~]# ll /var/lib/mysql total 91612 -rw-r----- 1 mysql mysql 196608 May 7 22:19 '#ib_16384_0.dblwr' -rw-r----- 1 mysql mysql 8585216 May 7 22:17 '#ib_16384_1.dblwr' drwxr-x--- 2 mysql mysql 4096 May 7 22:17 '#innodb_redo'/ drwxr-x--- 2 mysql mysql 4096 May 7 22:17 '#innodb_temp'/ drwx------ 7 mysql mysql 4096 May 7 22:17 ./ drwxr-xr-x 50 root root 4096 May 7 22:17 ../ -rw-r----- 1 mysql mysql 56 May 7 22:17 auto.cnf -rw-r----- 1 mysql mysql 180 May 7 22:17 binlog.000001 -rw-r----- 1 mysql mysql 404 May 7 22:17 binlog.000002 -rw-r----- 1 mysql mysql 157 May 7 22:17 binlog.000003 -rw-r----- 1 mysql mysql 48 May 7 22:17 binlog.index -rw------- 1 mysql mysql 1705 May 7 22:17 ca-key.pem -rw-r--r-- 1 mysql mysql 1112 May 7 22:17 ca.pem -rw-r--r-- 1 mysql mysql 1112 May 7 22:17 client-cert.pem -rw------- 1 mysql mysql 1705 May 7 22:17 client-key.pem -rw-r--r-- 1 root root 0 May 7 22:17 debian-5.7.flag -rw-r----- 1 mysql mysql 3425 May 7 22:17 ib_buffer_pool -rw-r----- 1 mysql mysql 12582912 May 7 22:17 ibdata1 -rw-r----- 1 mysql mysql 12582912 May 7 22:17 ibtmp1 drwxr-x--- 2 mysql mysql 4096 May 7 22:17 mysql/ -rw-r----- 1 mysql mysql 26214400 May 7 22:17 mysql.ibd drwxr-x--- 2 mysql mysql 4096 May 7 22:17 performance_schema/ -rw------- 1 mysql mysql 1709 May 7 22:17 private_key.pem -rw-r--r-- 1 mysql mysql 452 May 7 22:17 public_key.pem -rw-r--r-- 1 mysql mysql 1112 May 7 22:17 server-cert.pem -rw------- 1 mysql mysql 1705 May 7 22:17 server-key.pem drwxr-x--- 2 mysql mysql 4096 May 7 22:17 sys/ -rw-r----- 1 mysql mysql 5 May 7 22:17 ubuntu24-13.pid -rw-r----- 1 mysql mysql 16777216 May 7 22:19 undo_001 -rw-r----- 1 mysql mysql 16777216 May 7 22:19 undo_002查看数据库的数据文件 [root@ubuntu24-13:~]# ls /var/lib/mysql/mysql general_log.CSM general_log.CSV general_log_213.sdi slow_log.CSM slow_log.CSV slow_log_214.sdi 注意:因为这些文件,不是普通的文件系统,它是数据库专用的文件,只能通过数据库的统一接口到这些文件中,进行数据的查找。查看监听端口,默认3306,33060 是8.0版本中的特性 [root@ubuntu24-13:~]# netstat -tunlp | grep mysql tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN 8524/mysqld tcp 0 0 127.0.0.1:33060 0.0.0.0:* LISTEN 8524/mysqld 结果显示:默认监听的是本地主机的IP地址7.2.登录连接客户端连接: 默认用户名 root,默认密码为空连接到数据库里面 [root@ubuntu24-13:~]# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 8 Server version: 8.0.42-0ubuntu0.24.04.1 (Ubuntu) # 查看当前数据库的版本信息 mysql> select version(); +-------------------------+ | version() | +-------------------------+ | 8.0.42-0ubuntu0.24.04.1 | +-------------------------+ 1 row in set (0.00 sec) mysql> exit # 退出数据库的连接 Bye客户端连接: 直接使用用户和密码 [root@ubuntu24-13:~]# mysql -uroot -p Enter password: # 因为没有密码,所以这里直接Enter即可,也可以随便乱写密码 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 9 Server version: 8.0.42-0ubuntu0.24.04.1 (Ubuntu) Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> \s # 显示当前 MySQL 服务器会话状态的快捷命令 -------------- mysql Ver 8.0.42-0ubuntu0.24.04.1 for Linux on x86_64 ((Ubuntu)) Connection id: 9 Current database: Current user: root@localhost SSL: Not in use Current pager: stdout Using outfile: '' Using delimiter: ; Server version: 8.0.42-0ubuntu0.24.04.1 (Ubuntu) Protocol version: 10 Connection: Localhost via UNIX socket Server characterset: utf8mb4 Db characterset: utf8mb4 Client characterset: utf8mb4 Conn. characterset: utf8mb4 UNIX socket: /var/run/mysqld/mysqld.sock Binary data as: Hexadecimal Uptime: 7 min 11 sec Threads: 2 Questions: 8 Slow queries: 0 Opens: 119 Flush tables: 3 Open tables: 38 Queries per second avg: 0.018 --------------8.Ubuntu24中安装mysql8.0---二进制包安装8.1.如何获取二进制包文件传统的二进制包安装需要进行三步:configure --- make --- make install 而mysql的二进制包是指己经编译完成【也就是说,make已经做过了】,以压缩包提供下载的文件,下载到本 地之后释放到自定义目录,再进行配置即可。二进制包的下载位置 -- Download Archives 官网:https://dev.mysql.com/downloads选择 Download Archives选择第一个 Mysql Community Server选择第一个,然后点击右侧的下载就可以了 https://downloads.mysql.com/archives/get/p/23/file/mysql-8.4.0-linux-glibc2.28-x86_64.tar.xz以同样的逻辑下载mysql的最新版本9.2.0选择第一个,然后点击右侧的下载就可以了 https://downloads.mysql.com/archives/get/p/23/file/mysql-9.2.0-linux-glibc2.28-x86_64.tar.xz8.2.基础环境安装依赖 [root@ubuntu24-16:~]# apt -y install libaio-dev numactl libnuma-dev libncurses-dev注意:ubuntu24系统没有libaio1的包,需要单独去下载安装 curl -O http://launchpadlibrarian.net/646633572/libaio1_0.3.113-4_amd64.deb dpkg -i libaio1_0.3.113-4_amd64.deb8.3.用户环境[root@ubuntu24-16:~]# groupadd -r mysql [root@ubuntu24-16:~]# useradd -r -g mysql -s /sbin/nologin mysql8.4.软件安装获取软件 [root@ubuntu24-16:~]# mkdir -p /data/softs [root@ubuntu24-16:~]# cd /data/softs [root@ubuntu24-16:softs]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-8.4.0-linux-glibc2.28-x86_64.tar.xz解压至指定目录,这个目录只能写 /usr/local/ [root@ubuntu24-16:softs]# mkdir /usr/local/mysql [root@ubuntu24-16:softs]# tar xf mysql-8.4.0-linux-glibc2.28-x86_64.tar.xz [root@ubuntu24-16:softs]# mv mysql-8.4.0-linux-glibc2.28-x86_64 /usr/local/mysql查看文件 [root@ubuntu24-16:softs]# ls /usr/local/mysql LICENSE README bin docs include lib man share support-files [root@ubuntu24-16:softs]# ls /usr/local/mysql/bin/ ibd2sdi myisamchk mysql_config mysql_tzinfo_to_sql mysqld mysqldump mysqlslap innochecksum myisamlog mysql_config_editor mysqladmin mysqld-debug mysqldumpslow perror my_print_defaults myisampack mysql_migrate_keyring mysqlbinlog mysqld_multi mysqlimport myisam_ftdump mysql mysql_secure_installation mysqlcheck mysqld_safe mysqlshow8.5.环境变量设定-可选创建环境变量 [root@ubuntu24-16:softs]# echo 'PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh [root@ubuntu24-16:softs]# source /etc/profile.d/mysql.sh [root@ubuntu24-16:softs]# echo $PATH /usr/local/mysql/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin8.6.环境配置创建主配置文件 [root@ubuntu24-16:~]# mkdir /usr/local/mysql/etc [root@ubuntu24-16:~]# vim /usr/local/mysql/etc/my.cnf [root@ubuntu24-16:~]# cat /usr/local/mysql/etc/my.cnf [mysql] port = 3306 socket = /usr/local/mysql/data/mysql.sock [mysqld] port = 3306 mysqlx_port = 33060 mysqlx_socket = /usr/local/mysql/data/mysqlx.sock basedir = /usr/local/mysql datadir = /usr/local/mysql/data socket = /usr/local/mysql/data/mysql.sock pid-file = /usr/local/mysql/data/mysqld.pid log-error = /usr/local/mysql/log/error.log注意: 大家在互联网上经常看到的认证属性已经被移除了,但是,该密码插件选项依然很管用。 甚至默认的密码插件在集群操作的时候,不能用。 default-authentication-plugin = mysql_native_passwordmysqlx: 传统的 MySQL 客户端 - 服务器通信主要基于经典的 SQL 接口。随着现代应用开发需求的变化,如对JSON 数据类型的更好支持、更高效的文档存储和检索、以及更适合现代编程语言的 API 等,MySQL 引入了X DevAPI。而 mysqlx 就是与这个新 API 相关的重要部分,它提供了新的通信协议和客户端库,使得开发 者可以更方便地使用 MySQL 数据库。 使用 mysqlx 命令行客户端来测试和执行基于 X DevAPI 的操作。例如,通过该客户端可以使用新的语法进行数据库查询和操作。注意:配置文件中涉及到的配置目录,必须存在,否则无法运行创建数据目录创建依赖目录 [root@ubuntu24-16:~]# mkdir /usr/local/mysql/{data,log} 更改文件属性 [root@ubuntu24-16:~]# chown -R mysql:mysql /usr/local/mysql如果我们采用的是软连接的方式,上面赋权的时候,命令应该是: chown -R mysql:mysql /usr/local/mysql* 注意:mysql后面有一个 *,如果不加,会导致很多的权限问题,比如 2024-12-08T06:32:09.439274Z 0 [ERROR] [MY-010187] [Server] Could not open file '/data/server/mysql/logs/mysql.log' for error logging: Permission denied 2024-12-08T06:32:09.439380Z 0 [ERROR] [MY-013236] [Server] The designated data directory /data/server/mysql/data/ is unusable. You can remove all files that the server added to it. 2024-12-08T06:32:09.439412Z 0 [ERROR] [MY-010119] [Server] Aborting8.7.环境初始化8.7.1.密码初始化初始化,本地root用户 - 使用密码如果使用 --initialize 选项会生成随机密码,要去 /data/mysql/mysql.log中查看 如果使用 --initialize-insecure -选项会生成空密码[root@ubuntu24-16:~]# cd /usr/local/mysql/ [root@ubuntu24-16:mysql]# bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data确认登录密码 [root@ubuntu24-16:mysql]# grep 'temporary password' /usr/local/mysql/log/error.log 2025-05-07T14:55:15.598967Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: god&ia6haBrC8.7.2.空密码初始化初始化,本地root用户 - 使用空密码清理历史文件 [root@ubuntu24-16:~]# rm -rf /usr/local/mysql/data/* [root@ubuntu24-16:~]# mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data确认登录密码 [root@ubuntu24-16:~]# tail -f /usr/local/mysql/log/error.log ...... 2025-05-07T14:58:05.616373Z 6 [Warning] [MY-010453] [Server] root@localhost is created with an empty password ! Please consider switching off the --initialize-insecure option. 2025-05-07T14:58:07.889872Z 0 [System] [MY-015018] [Server] MySQL Server Initialization - end. 结果提示:使用的是空密码确认文件 [root@ubuntu24-16:~]# ls /usr/local/mysql/data/ '#ib_16384_0.dblwr' auto.cnf client-key.pem mysql.ibd public_key.pem undo_001 '#ib_16384_1.dblwr' ca-key.pem ib_buffer_pool mysql_upgrade_history server-cert.pem undo_002 '#innodb_redo' ca.pem ibdata1 performance_schema server-key.pem '#innodb_temp' client-cert.pem mysql private_key.pem sys8.8.服务脚本定制启动脚本该脚本不是systemd风格的脚本,但是可以被 systemd兼容 [root@ubuntu24-16:~]# cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld重载配置文件 [root@ubuntu24-16:~]# systemctl daemon-reload 启动mysqld服务 [root@ubuntu24-16:~]# /etc/init.d/mysqld start Starting mysqld (via systemctl): mysqld.service查看自动生成的服务管理文件 [root@ubuntu24-16:~]# systemctl cat mysqld.service # /run/systemd/generator.late/mysqld.service # Automatically generated by systemd-sysv-generator [Unit] Documentation=man:systemd-sysv-generator(8) SourcePath=/etc/init.d/mysqld Description=LSB: start and stop MySQL After=network-online.target After=remote-fs.target After=ypbind.service After=nscd.service After=ldap.service After=ntpd.service After=xntpd.service Wants=network-online.target [Service] Type=forking Restart=no TimeoutSec=5min IgnoreSIGPIPE=no KillMode=process GuessMainPID=no RemainAfterExit=yes SuccessExitStatus=5 6 ExecStart=/etc/init.d/mysqld start ExecStop=/etc/init.d/mysqld stop ExecReload=/etc/init.d/mysqld reload检测服务状态 [root@ubuntu24-16:~]# systemctl status mysqld ● mysqld.service - LSB: start and stop MySQL Loaded: loaded (/etc/init.d/mysqld; generated) Active: active (running) 查看端口连接 [root@ubuntu24-16:~]# netstat -tunlp | grep mysql tcp6 0 0 :::33060 :::* LISTEN 7349/mysqld tcp6 0 0 :::3306 :::* LISTEN 7349/mysqld8.9.连接测试客户端连接[root@ubuntu24-16:~]# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 9 Server version: 8.4.0 MySQL Community Server - GPL 查看当前的数据库版本 mysql> select version(); +-----------+ | version() | +-----------+ | 8.4.0 | +-----------+ 1 row in set (0.00 sec)修改密码 mysql> alter user root@'localhost' identified by 'Magedu'; Query OK, 0 rows affected (0.01 sec) mysql> exit Byemysql用户账号由两部分组成: 'USERNAME'@'HOST' dange@'10.0.0.100' dange@'10.0.0.%' dange@'%' 说明:HOST限制此用户可通过哪些远程主机连接mysql服务器确认修改密码效果默认情况下,无法登录了 [root@ubuntu24-16:~]# mysql ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)使用用户名和密码,可以正常登录 [root@ubuntu24-16:~]# mysql -uroot -pMagedu mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 11 Server version: 8.4.0 MySQL Community Server - GPL8.10.定制服务管理文件cat >/usr/lib/systemd/system/mysqld.service<<EOF [Unit] Description=MySQL Community Server Documentation=mysqld.service After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/usr/local/mysql/etc/my.cnf ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s TERM $MAINPID LimitNOFILE = 10000 EOF重载配置 [root@ubuntu24-16:~]# systemctl daemon-reload 启动服务 [root@ubuntu24-16:~]# systemctl start mysqld检测效果 [root@ubuntu24-16:~]# systemctl start mysqld.service [root@ubuntu24-16:~]# netstat -tunlp | grep 3306 tcp6 0 0 :::33060 :::* LISTEN 8503/mysqld tcp6 0 0 :::3306 :::* LISTEN 8503/mysqld [root@ubuntu24-16:~]# systemctl status mysqld ● mysqld.service - MySQL Community Server Loaded: loaded (/usr/lib/systemd/system/mysqld.service; disabled; preset: enabled) Active: active (running) since Thu 2025-05-08 10:07:35 CST; 21s ago Main PID: 8503 (mysqld) Tasks: 36 (limit: 4552) Memory: 429.7M (peak: 443.2M) CPU: 2.465s CGroup: /system.slice/mysqld.service └─8503 /usr/local/mysql/bin/mysqld --defaults-file=/usr/local/mysql/etc/my.cnf May 08 10:07:35 ubuntu24-16 systemd[1]: Started mysqld.service - MySQL Community Server.9.Ubuntu中安装mysql9.2---二进制包安装9.1.基础环境安装依赖 [root@ubuntu24-13:~]# apt -y install libaio-dev numactl libnuma-dev libncurses-dev注意:ubuntu24系统没有libaio1的包,需要单独去下载安装 [root@ubuntu24-13:~]# curl -O http://launchpadlibrarian.net/646633572/libaio1_0.3.113-4_amd64.deb [root@ubuntu24-13:~]# dpkg -i libaio1_0.3.113-4_amd64.deb 否则环境初始化的时候,会发生如下报错 root@ubuntu24:mysql# bin/mysqld --initialize --user=mysql -- basedir=/usr/local/mysql --datadir=/usr/local/mysql/data bin/mysqld: error while loading shared libraries: libaio.so.1: cannot open shared object file: No such file or directory9.2.用户环境创建组和用户 [root@ubuntu24-13:~]# groupadd -r mysql [root@ubuntu24-13:~]# useradd -r -g mysql -s /sbin/nologin mysql9.3.软件环境获取软件 [root@ubuntu24-13:~]# mkdir -p /data/softs [root@ubuntu24-13:~]# cd /data/softs [root@ubuntu24-13:softs]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-9.2.0-linux-glibc2.28-x86_64.tar.xz解压至指定目录,这个目录只能写 /usr/local/ [root@ubuntu24-13:softs]# ls mysql-9.2.0-linux-glibc2.28-x86_64.tar.xz [root@ubuntu24-13:softs]# tar xf mysql-9.2.0-linux-glibc2.28-x86_64.tar.xz [root@ubuntu24-13:softs]# mv mysql-9.2.0-linux-glibc2.28-x86_64 /usr/local/mysql查看文件 [root@ubuntu24-13:softs]# ls /usr/local/mysql LICENSE README bin docs include lib man share support-files [root@ubuntu24-13:softs]# ls /usr/local/mysql/bin/ ibd2sdi myisamchk mysql_config mysql_tzinfo_to_sql mysqld mysqldump mysqlslap innochecksum myisamlog mysql_config_editor mysqladmin mysqld-debug mysqldumpslow perror my_print_defaults myisampack mysql_migrate_keyring mysqlbinlog mysqld_multi mysqlimport myisam_ftdump mysql mysql_secure_installation mysqlcheck mysqld_safe mysqlshow9.4.环境变量设定-可选创建环境变量 [root@ubuntu24-13:~]# echo 'PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh [root@ubuntu24-13:~]# source /etc/profile.d/mysql.sh [root@ubuntu24-13:~]# echo $PATH /usr/local/mysql/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin9.5.环境配置创建主配置文件 [root@ubuntu24-13:~]# mkdir /usr/local/mysql/etc [root@ubuntu24-13:~]# vim /usr/local/mysql/etc/my.cnf [root@ubuntu24-13:~]# cat /usr/local/mysql/etc/my.cnf [mysql] port = 3306 socket = /usr/local/mysql/data/mysql.sock [mysqld] port = 3306 mysqlx_port = 33060 mysqlx_socket = /usr/local/mysql/data/mysqlx.sock basedir = /usr/local/mysql datadir = /usr/local/mysql/data socket = /usr/local/mysql/data/mysql.sock pid-file = /usr/local/mysql/data/mysqld.pid log-error = /usr/local/mysql/log/error.log注意: 大家在互联网上经常看到的认证属性已经被移除了,但是,该密码插件选项依然很管用。 甚至默认的密码插件在集群操作的时候,不能用。 default-authentication-plugin = mysql_native_password注意:配置文件中涉及到的配置目录,必须存在,否则无法运行创建数据目录创建依赖目录 [root@ubuntu24-13:~]# mkdir /usr/local/mysql/{data,log} 更改文件属性 [root@ubuntu24-13:~]# chown -R mysql:mysql /usr/local/mysql/如果我们采用的是软连接的方式,上面赋权的时候,命令应该是: chown -R mysql:mysql /usr/local/mysql* 注意:mysql后面有一个 *,如果不加,会导致很多的权限问题,比如 2025-05-08T06:32:09.439274Z 0 [ERROR] [MY-010187] [Server] Could not open file '/data/server/mysql/logs/mysql.log' for error logging: Permission denied 2025-05-08T06:32:09.439380Z 0 [ERROR] [MY-013236] [Server] The designated data directory /data/server/mysql/data/ is unusable. You can remove all files that the server added to it. 2025-05-08T06:32:09.439412Z 0 [ERROR] [MY-010119] [Server] Aborting9.6.环境初始化9.6.1.密码初始化初始化,本地root用户 - 使用密码如果使用 --initialize 选项会生成随机密码,要去 /data/mysql/mysql.log中查看 如果使用 --initialize-insecure -选项会生成空密码[root@ubuntu24-13:~]# cd /usr/local/mysql/ [root@ubuntu24-13:mysql]# bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data确认登录密码 [root@ubuntu24-13:mysql]# grep 'temporary password' /usr/local/mysql/log/error.log 2025-05-08T02:27:47.810610Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: msgQ:*jwk1Kb9.6.2.空密码初始化初始化,本地root用户 - 使用空密码清理历史文件 [root@ubuntu24-13:mysql]# rm -rf /usr/local/mysql/data/* [root@ubuntu24-13:mysql]# bin/mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data确认登录密码 [root@ubuntu24-13:mysql]# tail -f /usr/local/mysql/log/error.log ...... 2025-05-08T02:30:16.497848Z 6 [Warning] [MY-010453] [Server] root@localhost is created with an empty password ! Please consider switching off the --initialize-insecure option. 2025-05-08T02:30:18.762028Z 0 [System] [MY-015018] [Server] MySQL Server Initialization - end. 结果提示:使用的是空密码确认文件 [root@ubuntu24-13:~]# ls /usr/local/mysql/data/ | xargs -n 3 printf "%-30s %-30s %-30s\n" #ib_16384_0.dblwr #ib_16384_1.dblwr #innodb_redo #innodb_temp auto.cnf ca-key.pem ca.pem client-cert.pem client-key.pem ib_buffer_pool ibdata1 mysql mysql.ibd mysql_upgrade_history performance_schema private_key.pem public_key.pem server-cert.pem server-key.pem sys undo_001 undo_0029.7.服务脚本定制启动脚本该脚本不是systemd风格的脚本,但是可以被 systemd兼容 [root@ubuntu24-13:~]# cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld 重载配置文件 [root@ubuntu24-13:~]# systemctl daemon-reload 启动mysqld服务 [root@ubuntu24-13:~]# /etc/init.d/mysqld start Starting mysqld (via systemctl): mysqld.service.查看自动生成的服务管理文件 [root@ubuntu24-13:~]# systemctl cat mysqld.service # /run/systemd/generator.late/mysqld.service # Automatically generated by systemd-sysv-generator [Unit] Documentation=man:systemd-sysv-generator(8) SourcePath=/etc/init.d/mysqld Description=LSB: start and stop MySQL After=network-online.target After=remote-fs.target After=ypbind.service After=nscd.service After=ldap.service After=ntpd.service After=xntpd.service Wants=network-online.target [Service] Type=forking Restart=no TimeoutSec=5min IgnoreSIGPIPE=no KillMode=process GuessMainPID=no RemainAfterExit=yes SuccessExitStatus=5 6 ExecStart=/etc/init.d/mysqld start ExecStop=/etc/init.d/mysqld stop ExecReload=/etc/init.d/mysqld reload检测服务状态 [root@ubuntu24-13:~]# systemctl status mysqld.service ● mysqld.service - LSB: start and stop MySQL Loaded: loaded (/etc/init.d/mysqld; generated) Active: active (running) 查看端口连接 [root@ubuntu24-13:~]# netstat -tunlp | grep mysql tcp6 0 0 :::33060 :::* LISTEN 8114/mysqld tcp6 0 0 :::3306 :::* LISTEN 8114/mysqld9.8.连接测试客户端连接 [root@ubuntu24-13:~]# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 9 Server version: 9.2.0 MySQL Community Server - GPL Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>查看当前的数据库版本 mysql> select version(); +-----------+ | version() | +-----------+ | 9.2.0 | +-----------+ 1 row in set (0.00 sec) 修改密码 mysql> alter user root@'localhost' identified by 'Magedu'; Query OK, 0 rows affected (0.01 sec) mysql> exit Bye确认修改密码效果默认情况下,无法登录了 [root@ubuntu24-13:~]# mysql ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO) 使用用户名和密码,可以正常登录 [root@ubuntu24-13:~]# mysql -uroot -pMagedu mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 11 Server version: 9.2.0 MySQL Community Server - GPL Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>9.9.定制服务管理文件cat >/usr/lib/systemd/system/mysqld.service<<EOF [Unit] Description=MySQL Community Server Documentation=mysqld.service After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/usr/local/mysql/etc/my.cnf ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s TERM $MAINPID LimitNOFILE = 10000 EOF重载配置 [root@ubuntu24-13:~]# systemctl daemon-reload 启动服务 [root@ubuntu24-13:~]# systemctl start mysqld 查看端口情况 [root@ubuntu24-13:~]# netstat -tunlp | grep 3306 tcp6 0 0 :::33060 :::* LISTEN 8114/mysqld tcp6 0 0 :::3306 :::* LISTEN 8114/mysqld查看服务状态信息 [root@ubuntu24-13:~]# systemctl status mysqld.service ● mysqld.service - MySQL Community Server Loaded: loaded (/usr/lib/systemd/system/mysqld.service; disabled; preset: enabled) Active: active (running) 10.Rocky9中安装mysql8.0---二进制包安装10.1.基础环境安装依赖 [root@Rocky9-12 ~]# yum -y install libaio numactl-libs ncurses-compat-libs10.2.用户环境创建组和用户 [root@Rocky9-12 ~]# groupadd -r mysql [root@Rocky9-12 ~]# useradd -r -g mysql -s /sbin/nologin mysql10.3.软件环境获取软件 [root@Rocky9-12 ~]# mkdir -p /data/softs [root@Rocky9-12 ~]# cd /data/softs [root@Rocky9-12 softs]#wget https://downloads.mysql.com/archives/get/p/23/file/mysql-9.2.0-linux-glibc2.28-x86_64.tar.xzz解压至指定目录,这个目录只能写 /usr/local/ [root@Rocky9-12 softs]# ls mysql-9.2.0-linux-glibc2.28-x86_64.tar.xz [root@Rocky9-12 softs]# tar xf mysql-9.2.0-linux-glibc2.28-x86_64.tar.xz [root@Rocky9-12 softs]# mv mysql-9.2.0-linux-glibc2.28-x86_64 /usr/local/mysql[root@Rocky9-12 softs]# ls /usr/local/mysql bin docs include lib LICENSE man README share support-files [root@Rocky9-12 softs]# ls /usr/local/mysql/bin/ | xargs -n 3 printf "%-30s %-30s %-30s\n" ibd2sdi innochecksum myisamchk myisam_ftdump myisamlog myisampack my_print_defaults mysql mysqladmin mysqlbinlog mysqlcheck mysql_config mysql_config_editor mysqld mysqld-debug mysqld_multi mysqld_safe mysqldump mysqldumpslow mysqlimport mysql_migrate_keyring mysql_secure_installation mysqlshow mysqlslap10.4.环境变量设定--可选创建环境变量 [root@Rocky9-12 ~]# echo 'PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh [root@Rocky9-12 ~]# source /etc/profile.d/mysql.sh [root@Rocky9-12 ~]# echo $PATH /usr/local/mysql/bin:/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin10.5.环境配置创建主配置文件 [root@Rocky9-12 ~]# mkdir /usr/local/mysql/etc [root@Rocky9-12 ~]# vim /usr/local/mysql/etc/my.cnf [root@Rocky9-12 ~]# cat /usr/local/mysql/etc/my.cnf [mysql] port = 3306 socket = /usr/local/mysql/data/mysql.sock [mysqld] port = 3306 mysqlx_port = 33060 mysqlx_socket = /usr/local/mysql/data/mysqlx.sock basedir = /usr/local/mysql datadir = /usr/local/mysql/data socket = /usr/local/mysql/data/mysql.sock pid-file = /usr/local/mysql/data/mysqld.pid log-error = /usr/local/mysql/log/error.log创建数据目录创建依赖目录 [root@Rocky9-12 ~]# mkdir /usr/local/mysql/{data,log} 更改文件属性 [root@Rocky9-12 ~]# chown -R mysql:mysql /usr/local/mysql/10.6.环境初始化10.6.1.密码初始化[root@Rocky9-12 ~]# cd /usr/local/mysql/ [root@Rocky9-12 mysql]# bin/mysqld -initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data 确认登录密码 [root@Rocky9-12 mysql]# grep 'temporary password' /usr/local/mysql/log/error.log 2025-05-08T02:59:08.664100Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: cZYk#4#T)2k710.6.2.空密码初始化初始化,本地root用户 - 使用空密码清理历史文件 [root@Rocky9-12 mysql]# rm -rf /usr/local/mysql/data/* [root@Rocky9-12 mysql]# bin/mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data确认登录密码 [root@Rocky9-12 mysql]# tail -f /usr/local/mysql/log/error.log ...... 2025-05-08T03:00:45.561141Z 6 [Warning] [MY-010453] [Server] root@localhost is created with an empty password ! Please consider switching off the --initialize-insecure option. 2025-05-08T03:00:47.872042Z 0 [System] [MY-015018] [Server] MySQL Server Initialization - end. 结果显示:为空密码确认文件 [root@Rocky9-12 ~]# ls /usr/local/mysql/data/ | xargs -n 3 printf "%-30s %-30s %-30s\n" auto.cnf ca-key.pem ca.pem client-cert.pem client-key.pem #ib_16384_0.dblwr #ib_16384_1.dblwr ib_buffer_pool ibdata1 #innodb_redo #innodb_temp mysql mysql.ibd mysql_upgrade_history performance_schema private_key.pem public_key.pem server-cert.pem server-key.pem sys undo_001 undo_00210.7.定制服务管理文件cat >/usr/lib/systemd/system/mysqld.service<<EOF [Unit] Description=MySQL Community Server Documentation=mysqld.service After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/usr/local/mysql/etc/my.cnf ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s TERM $MAINPID LimitNOFILE = 10000 EOF重载配置 [root@Rocky9-12 ~]# systemctl daemon-reload 启动mysql [root@Rocky9-12 ~]# systemctl start mysqld.service 查看端口连接 [root@Rocky9-12 ~]# netstat -tunlp | grep 3306 tcp6 0 0 :::33060 :::* LISTEN 2052/mysqld tcp6 0 0 :::3306 :::* LISTEN 2052/mysqld10.8.连接测试[root@Rocky9-12 ~]# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 9 Server version: 9.2.0 MySQL Community Server - GPL Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. 查看当前的数据库版本 mysql> select version(); +-----------+ | version() | +-----------+ | 9.2.0 | +-----------+ 1 row in set (0.00 sec)修改密码 mysql> alter user root@'localhost' identified by 'Magedu'; Query OK, 0 rows affected (0.00 sec) mysql> exit Bye默认情况下,无法登录了 [root@Rocky9-12 ~]# mysql ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)使用用户名和密码,可以正常登录 [root@Rocky9-12 ~]# mysql -uroot -pMagedu mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 11 Server version: 9.2.0 MySQL Community Server - GPL Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> exit Bye11.Rocky9-12二进制格式安装 MySQL 5.7.4411.1.基础环境安装依赖 [root@Rocky9-12 ~]# yum -y install libaio numactl-libs ncurses-compat-libs11.2.准备用户创建组和用户 [root@Rocky9-12 softs]# groupadd -r mysql [root@Rocky9-12 softs]# useradd -r -g mysql -s /sbin/nologin mysql11.3.软件环境获取软件 [root@Rocky9-12 ~]# mkdir -p /data/softs [root@Rocky9-12 ~]# cd /data/softs [root@Rocky9-12 softs]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz解压至指定目录,这个目录只能写 /usr/local/ [root@Rocky9-12 softs]# ls mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz [root@Rocky9-12 softs]# tar xf mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz [root@Rocky9-12 softs]# mv mysql-5.7.44-linux-glibc2.12-x86_64 /usr/local/mysql11.4.环境变量设定-可选[root@Rocky9-12 softs]# echo 'PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh [root@Rocky9-12 softs]# source /etc/profile.d/mysql.sh [root@Rocky9-12 softs]# echo $PATH /usr/local/mysql/bin:/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin11.5.环境配置创建主配置文件 [root@Rocky9-12 softs]# mkdir /usr/local/mysql/etc [root@Rocky9-12 softs]# vim /usr/local/mysql/etc/my.cnf [root@Rocky9-12 softs]# cat /usr/local/mysql/etc/my.cnf [mysqld] port=3306 socket = /usr/local/mysql/data/mysql.sock user=mysql basedir = /usr/local/mysql datadir = /usr/local/mysql/data skip_name_resolve = 1 pid-file = /usr/local/mysql/data/mysqld.pid log-error = /usr/local/mysql/log/error.log [client] socket = /usr/local/mysql/data/mysql.sock11.6.创建数据目录,建议使用逻辑卷创建依赖目录 [root@Rocky9-12 softs]# mkdir /usr/local/mysql/{data,log} 更改文件属性 [root@Rocky9-12 softs]# chown -R mysql:mysql /usr/local/mysql/11.7.环境初始化11.7.1.密码初始化[root@Rocky9-12 ~]# cd /usr/local/mysql/bin [root@Rocky9-12 bin]# /usr/local/mysql/bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data确认登录密码 [root@Rocky9-12 bin]# grep 'temporary password' /usr/local/mysql/log/error.log 2025-05-08T11:36:50.323892Z 1 [Note] A temporary password is generated for root@localhost: p>(D,oCOv1;U11.7.2.空密码初始化初始化,本地root用户 - 使用空密码清理历史文件 [root@Rocky9-12 bin]# rm -rf /usr/local/mysql/data/* [root@Rocky9-12 bin]# mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data确认登录密码 [root@Rocky9-12 bin]# tail /usr/local/mysql/log/error.log ...... 2025-05-08T11:38:56.196531Z 1 [Warning] root@localhost is created with an empty password ! Please consider switching off the --initialize-insecure option. 结果显示:为空密码确认文件 [root@Rocky9-12 bin]# ls /usr/local/mysql/data/ | xargs -n 3 printf "%-30s %-30s %-30s\n" auto.cnf ca-key.pem ca.pem client-cert.pem client-key.pem ib_buffer_pool ibdata1 ib_logfile0 ib_logfile1 mysql performance_schema private_key.pem public_key.pem server-cert.pem server-key.pem sys11.8.定制服务管理文件cat >/usr/lib/systemd/system/mysqld.service<<EOF [Unit] Description=MySQL Community Server Documentation=mysqld.service After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/usr/local/mysql/etc/my.cnf ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s TERM $MAINPID LimitNOFILE = 10000 EOF重载配置 [root@Rocky9-12 bin]# systemctl daemon-reload 启动mysql [root@Rocky9-12 bin]# systemctl start mysqld.service 查看端口连接 [root@Rocky9-12 bin]# netstat -tunlp | grep 3306 tcp6 0 0 :::3306 :::* LISTEN 1935/mysqld11.9.连接测试[root@Rocky9-12 bin]# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.44 MySQL Community Server (GPL) Copyright (c) 2000, 2023, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>查看当前数据库版本 mysql> select version(); +-----------+ | version() | +-----------+ | 5.7.44 | +-----------+ 1 row in set (0.00 sec)修改密码 mysql> alter user root@'localhost' identified by 'Magedu'; Query OK, 0 rows affected (0.00 sec) mysql> exit Bye使用用户名和密码进行登录 [root@Rocky9-12 bin]# mysql -uroot -pMagedu mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.44 MySQL Community Server (GPL) Copyright (c) 2000, 2023, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> exit Bye12.ubuntu24-13二进制格式安装 MySQL 5.7.4412.1.基础环境安装依赖 [root@ubuntu24-13:~]# apt -y install libaio-dev12.2.准备用户创建组和用户 [root@ubuntu24-13:~]# groupadd -r mysql [root@ubuntu24-13:~]# useradd -r -g mysql -s /sbin/nologin mysql12.3.软件环境获取软件 [root@ubuntu24-13:~]# mkdir -p /data/softs [root@ubuntu24-13:~]# cd /data/softs [root@ubuntu24-13:softs]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz解压至指定目录,这个目录只能写 /usr/local/ [root@ubuntu24-13:softs]# ls mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz [root@ubuntu24-13:softs]# tar xf mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz [root@ubuntu24-13:softs]# mv mysql-5.7.44-linux-glibc2.12-x86_64 /usr/local/mysql12.4.环境变量设定-可选[root@ubuntu24-13:softs]# echo 'PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh [root@ubuntu24-13:softs]# source /etc/profile.d/mysql.sh [root@ubuntu24-13:softs]# echo $PATH /usr/local/mysql/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin12.5.环境配置创建主配置文件 [root@ubuntu24-13:softs]# mkdir /usr/local/mysql/etc [root@ubuntu24-13:softs]# vim /usr/local/mysql/etc/my.cnf [root@ubuntu24-13:softs]# cat /usr/local/mysql/etc/my.cnf [mysqld] port=3306 user=mysql character-set-server=utf8 collation-server=utf8_general_ci default-storage-engine=INNODB # Only allow connections from localhost bind-address = 0.0.0.0 #sql_mode="ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" sql_mode="STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" max_connections=100 #skip-name-resolve socket = /usr/local/mysql/data/mysql.sock basedir = /usr/local/mysql datadir = /usr/local/mysql/data #日志 #日志时间,默认是UTC log_timestamps=SYSTEM #错误日志 log-error = /usr/local/mysql/log/error.log #开启二进制日志 log-bin=/usr/local/mysql/mysql-bin server-id=1 #开启通用查询日志 #general_log=ON #general_log_file=/usr/local/mysql/mysql-query.log #慢查询日志 slow_query_log=ON slow_query_log_file=/usr/local/var/log/mysql/mysql-slow.log long_query_time=1 #记录不使用索引查询的语句 log_queries_not_using_indexes=ON #修改密码校验等级 plugin-load-add=validate_password.so validate-password=FORCE_PLUS_PERMANENT validate_password_policy=0 validate_password_length=4 #设置导入导出的安全目录 secure_file_priv="" skip_name_resolve = 1 pid-file = /usr/local/mysql/data/mysqld.pid [mysql] default-character-set=utf8 auto-rehash [client] port=3306 socket = /usr/local/mysql/data/mysql.sock其中log_error文件需要事先创建,同时注意文件权限为mysql12.6.创建数据目录,建议使用逻辑卷创建依赖目录 [root@ubuntu24-13:softs]# mkdir /usr/local/mysql/{data,log} 更改文件属性 [root@ubuntu24-13:softs]# chown -R mysql:mysql /usr/local/mysql/12.7.环境初始化密码初始化[root@ubuntu24-13:~]# cd /usr/local/mysql/bin [root@ubuntu24-13:~]# /usr/local/mysql/bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data确认登录密码 [root@ubuntu24-13:~]# grep 'temporary password' /usr/local/mysql/log/error.log 2025-05-09T13:33:21.997935+08:00 1 [Note] A temporary password is generated for root@localhost: ,?ssSMZ)z419报错: [root@ubuntu24-13:~]# /usr/local/mysql/bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data /usr/local/mysql/bin/mysqld: error while loading shared libraries: libaio.so.1: cannot open shared object file: No such file or directory 解决问题: 这是由于系统安装的版本过高。通过建立软连接方式解决 查看自己系统下对应的版本,建立软连接 [root@ubuntu24-13:~]# ldd /usr/local/mysql/bin/mysqld | grep libaio libaio.so.1 => not found [root@ubuntu24-13:~]# find / -name libaio.so* /usr/lib/x86_64-linux-gnu/libaio.so.1t64 /usr/lib/x86_64-linux-gnu/libaio.so.1t64.0.2 /usr/lib/x86_64-linux-gnu/libaio.so # 创建软链接 [root@ubuntu24-13:~]# ln -s /usr/lib/x86_64-linux-gnu/libaio.so /usr/lib/x86_64-linux-gnu/libaio.so.1 # 检查库是否存在 [root@ubuntu24-13:~]# ll /lib/x86_64-linux-gnu/libaio.so.1 lrwxrwxrwx 1 root root 35 May 9 13:25 /lib/x86_64-linux-gnu/libaio.so.1 -> /usr/lib/x86_64-linux-gnu/libaio.so # 验证动态链接器能否找到库 [root@ubuntu24-13:~]# ldd /usr/local/mysql/bin/mysqld | grep libaio libaio.so.1 => /lib/x86_64-linux-gnu/libaio.so.1 (0x00007c61e38ec000)报错: [root@ubuntu24-13:~]# mysql mysql: error while loading shared libraries: libncurses.so.5: cannot open shared object file: No such file or directory [root@ubuntu24-13:~]# ln -s /usr/lib/x86_64-linux-gnu/libncurses.so.6.4 /usr/lib/x86_64-linux-gnu/libncurses.so.5 [root@ubuntu24-13:~]# ln -s /usr/lib/x86_64-linux-gnu/libtinfo.so.6.4 /usr/lib/x86_64-linux-gnu/libtinfo.so.5确认文件 [root@ubuntu24-13:~]# ls /usr/local/mysql/data/ | xargs -n 3 printf "%-30s %-30s %-30s\n" auto.cnf ca-key.pem ca.pem client-cert.pem client-key.pem ib_buffer_pool ib_logfile0 ib_logfile1 ibdata1 mysql performance_schema private_key.pem public_key.pem server-cert.pem server-key.pem sys12.8.定制服务管理文件cat >/usr/lib/systemd/system/mysqld.service<<EOF [Unit] Description=MySQL Community Server Documentation=mysqld.service After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/usr/local/mysql/etc/my.cnf ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s TERM $MAINPID LimitNOFILE = 10000 EOF重载配置 [root@ubuntu24-13:~]# systemctl daemon-reload 启动mysql [root@ubuntu24-13:~]# systemctl start mysqld.service 查看端口连接 [root@ubuntu24-13:~]# netstat -tunlp | grep 3306 tcp6 0 0 :::3306 :::* LISTEN 1935/mysqld12.9.连接测试[root@ubuntu24-13:~]# mysql -uroot -p",?ssSMZ)z419" mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.44-log Copyright (c) 2000, 2023, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>查看当前数据库版本 mysql> select version(); +-----------+ | version() | +-----------+ | 5.7.44 | +-----------+ 1 row in set (0.00 sec)修改密码并授予权限 mysql> alter user root@'localhost' identified by 'Mysql.123456'; Query OK, 0 rows affected (0.01 sec) mysql> grant all privileges on *.* to root@'%' identified by 'Mysql.123456'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) mysql> exit Bye[root@ubuntu24-13:~]# mysql -uroot -p'Mysql.123456' mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.44-log MySQL Community Server (GPL) Copyright (c) 2000, 2023, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> exit Bye13.通用二进制格式安装 MySQL 5.6.5013.1.基础环境安装依赖 [root@Rocky9-12 ~]# yum install -y perl-Data-Dumper autoconf libaio perl-Sys-Hostname ncurses-compat-libs常见错误:缺少安装依赖,会报如下错误 [root@Rocky9-12 mysql]# ./scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data FATAL ERROR: please install the following Perl modules before executing ./scripts/mysql_install_db: Sys::Hostname[root@Rocky9-12 ~]# mysql mysql: error while loading shared libraries: libncurses.so.5: cannot open shared object file: No such file or directory [root@Rocky9-12 ~]# mysql -uroot -p mysql: error while loading shared libraries: libncurses.so.5: cannot open shared object file: No such file or directory 在 Rocky Linux 9 系统中,可以使用 dnf 命令安装 libncurses5 相关的包。不过 Rocky Linux 9 中可能没有直接提供 libncurses.so.5 版本,你可以尝试安装兼容的 ncurses 包: sudo dnf install ncurses-compat-libs 这个包通常会包含 libncurses.so.5 或者提供其兼容的版本。13.2.准备用户创建组和用户 [root@Rocky9-12 ~]# groupadd -r mysql [root@Rocky9-12 ~]# useradd -r -g mysql -s /sbin/nologin mysql13.3.软件环境获取软件 [root@Rocky9-12 ~]# mkdir -p /data/softs [root@Rocky9-12 ~]# cd /data/softs [root@Rocky9-12 softs]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.6.50-linux-glibc2.12-x86_64.tar.gz解压至指定目录,这个目录只能写 /usr/local/ [root@Rocky9-12 softs]# ls mysql-5.6.50-linux-glibc2.12-x86_64.tar.gz [root@Rocky9-12 softs]# tar xf mysql-5.6.50-linux-glibc2.12-x86_64.tar.gz [root@Rocky9-12 softs]# mv mysql-5.6.50-linux-glibc2.12-x86_64 /usr/local/mysql13.4.环境变量设定--可选[root@Rocky9-12 softs]# echo 'PATH=/usr/local/mysql/bin:$PATH' > /etc/profile.d/mysql.sh [root@Rocky9-12 softs]# source /etc/profile.d/mysql.sh [root@Rocky9-12 softs]# echo $PATH /usr/local/mysql/bin:/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin13.5.环境配置创建主配置文件 [root@Rocky9-12 softs]# mkdir /usr/local/mysql/etc [root@Rocky9-12 softs]# vim /usr/local/mysql/etc/my.cnf [root@Rocky9-12 softs]# cat /usr/local/mysql/etc/my.cnf [mysqld] port=3306 socket = /usr/local/mysql/data/mysql.sock user=mysql basedir = /usr/local/mysql datadir = /usr/local/mysql/data innodb_file_per_table=on skip_name_resolve = on symbolic-links=0 [client] socket = /usr/local/mysql/data/mysql.sock [mysqld_safe] pid-file = /usr/local/mysql/data/mysqld.pid log-error = /usr/local/mysql/log/error.log13.6.创建数据目录,建议使用逻辑卷创建依赖目录 [root@Rocky9-12 softs]# mkdir /usr/local/mysql/{data,log} 更改文件属性 [root@Rocky9-12 softs]# chown -R mysql:mysql /usr/local/mysql/13.7.环境初始化[root@Rocky9-12 softs]# cd /usr/local/mysql [root@Rocky9-12 mysql]# ./scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data FATAL ERROR: please install the following Perl modules before executing ./scripts/mysql_install_db: Sys::Hostname确认文件 [root@Rocky9-12 mysql]# ll /usr/local/mysql/data/ total 110600 -rw-rw---- 1 mysql mysql 12582912 May 8 20:06 ibdata1 -rw-rw---- 1 mysql mysql 50331648 May 8 20:06 ib_logfile0 -rw-rw---- 1 mysql mysql 50331648 May 8 20:06 ib_logfile1 drwx------ 2 mysql mysql 4096 May 8 20:06 mysql drwx------ 2 mysql mysql 4096 May 8 20:06 performance_schema drwxr-xr-x 2 mysql mysql 20 May 8 19:56 test13.8.定制服务管理文件cat >/usr/lib/systemd/system/mysqld.service<<EOF [Unit] Description=MySQL Community Server Documentation=mysqld.service After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/usr/local/mysql/etc/my.cnf ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s TERM $MAINPID LimitNOFILE = 10000 EOF重载配置 [root@Rocky9-12 bin]# systemctl daemon-reload 启动mysql [root@Rocky9-12 bin]# systemctl start mysqld.service 查看端口连接 [root@Rocky9-12 bin]# netstat -tunlp | grep 3306 tcp6 0 0 :::3306 :::* LISTEN 1935/mysqld13.9.连接测试[root@Rocky9-12 ~]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 Server version: 5.6.50 MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>查看当前版本信息 mysql> select version(); +-----------+ | version() | +-----------+ | 5.6.50 | +-----------+ 1 row in set (0.01 sec)修改密码 mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) mysql> set password for 'root'@'localhost'=password('123456'); Query OK, 0 rows affected (0.01 sec) mysql> exit Bye-- 刷新权限表 FLUSH PRIVILEGES; -- 修改 root 用户在 localhost 上的密码 SET PASSWORD FOR 'root'@'localhost' = PASSWORD('123456');使用用户名和密码进行登录 [root@Rocky9-12 ~]# mysql -uroot -p123456 Warning: Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.6.50 MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> exit Bye13.10.初始化脚本提高安全性范例: 针对MySQL5.6前版本进行安全加固运行脚本:mysql_secure_installation 设置数据库管理员root口令 禁止root远程登录 删除anonymous用户帐号 删除test数据库[root@Rocky9-12 ~]# mysql -uroot -pMagedu Warning: Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.6.50 MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | test | +--------------------+ 4 rows in set (0.00 sec) mysql> select user,host from mysql.user; +------+-----------+ | user | host | +------+-----------+ | root | 127.0.0.1 | | root | ::1 | | | localhost | | root | localhost | | | rocky9-12 | | root | rocky9-12 | +------+-----------+ 6 rows in set (0.00 sec) mysql> exit Bye[root@Rocky9-12 ~]# file `which mysql_secure_installation` /usr/local/mysql/bin/mysql_secure_installation: Perl script text executable做个软链接,默认文件为/tmp/mysql.sock,否则会报如下错误 下面直接指定socket文件路径,也不行 [root@Rocky9-12 ~]# ln -s /usr/local/mysql/data/mysql.sock /tmp/mysql.sock [root@Rocky9-12 ~]# ll /tmp/mysql.sock lrwxrwxrwx 1 root root 32 May 8 21:08 /tmp/mysql.sock -> /usr/local/mysql/data/mysql.sock 错误: [root@Rocky9-12 ~]# /usr/local/mysql/bin/mysql_secure_installation --socket=/usr/local/mysql/data/mysql.sock NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MySQL SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY! In order to log into MySQL to secure it, we'll need the current password for the root user. If you've just installed MySQL, and you haven't set the root password yet, the password will be blank, so you should just press enter here. Enter current password for root (enter for none): ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) Enter current password for root (enter for none): ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) Enter current password for root (enter for none): ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) Unable to connect to the server as root user, giving up. Cleaning up...[root@Rocky9-12 ~]# /usr/local/mysql/bin/mysql_secure_installation NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MySQL SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY! In order to log into MySQL to secure it, we'll need the current password for the root user. If you've just installed MySQL, and you haven't set the root password yet, the password will be blank, so you should just press enter here. Enter current password for root (enter for none): OK, successfully used password, moving on... Setting the root password ensures that nobody can log into the MySQL root user without the proper authorisation. You already have a root password set, so you can safely answer 'n'. Change the root password? [Y/n] y New password: Re-enter new password: Password updated successfully! Reloading privilege tables.. ... Success! By default, a MySQL installation has an anonymous user, allowing anyone to log into MySQL without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? [Y/n] y ... Success! Normally, root should only be allowed to connect from 'localhost'. This ensures that someone cannot guess at the root password from the network. Disallow root login remotely? [Y/n] y ... Success! By default, MySQL comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. Remove test database and access to it? [Y/n] y - Dropping test database... ... Success! - Removing privileges on test database... ... Success! Reloading the privilege tables will ensure that all changes made so far will take effect immediately. Reload privilege tables now? [Y/n] y ... Success! All done! If you've completed all of the above steps, your MySQL installation should now be secure. Thanks for using MySQL! Cleaning up...14.常见的报错信息14.1.报错信息[root@Rocky9-12 ~]#echo $PATH /root/.local/bin:/root/bin:/usr/local/mysql/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin [root@Rocky9-12 ~]# whereis mysqld mysqld: /usr/local/mysql/bin/mysqld [root@Rocky9-12 ~]# ll /usr/local/mysql/bin/mysqld -rwxr-xr-x 1 mysql mysql 211661577 Oct 11 2023 /usr/local/mysql/bin/mysqld [root@Rocky9-12 ~]# mysqld -bash: /usr/local/mysql/bin/mysqld: No such file or directory文件存在,但提示文件一直提示找不到14.2.分析问题当你使用 whereis 命令能找到 mysqld 的路径,并且通过 ll 命令能看到该文件确实存在,但执行 mysqld 时却提示 “No such file or directory”,这通常不是文件本身不存在,而是因为缺少该程序运行所需的依赖库或者动态链接库路径配置有误。下面为你详细分析可能的原因及解决办法:1. 缺少 32 位兼容库 如果 mysqld 是 32 位程序,而你的系统是 64 位的,可能会因为缺少 32 位兼容库而导致找不到依赖的动态链接器。 解决办法: 在 Rocky Linux 9 系统中,你可以使用以下命令安装 32 位兼容库: dnf install -y glibc.i6862. 动态链接库路径配置问题 mysqld 程序可能依赖于某些特定的动态链接库,而这些库的路径没有被正确配置到系统的动态链接库搜索路径中。 解决办法: 临时解决:使用 LD_LIBRARY_PATH 环境变量来临时指定动态链接库的搜索路径。例如,如果 mysqld 依赖的库在 /usr/local/mysql/lib 目录下,可以执行以下命令: export LD_LIBRARY_PATH=/usr/local/mysql/lib:$LD_LIBRARY_PATH mysqld 永久解决:创建一个新的.conf文件,将动态链接库的路径添加到该文件中,然后更新动态链接库缓存。 echo "/usr/local/mysql/lib" > /etc/ld.so.conf.d/mysql.conf ldconfig3. 文件损坏 mysqld 文件本身可能已经损坏,导致系统无法正确执行。4. SELinux 或防火墙限制 SELinux 或者防火墙可能会阻止 mysqld 程序的执行。 解决办法 SELinux:可以临时禁用 SELinux 来进行测试: setenforce 0 如果禁用 SELinux 后 mysqld 能够正常执行,你可以修改 SELinux 的策略来允许 mysqld 运行。 防火墙:确保防火墙没有阻止 mysqld 所需的端口(默认是 3306)。可以使用以下命令开放端口: firewall-cmd --zone=public --add-port=3306/tcp --permanent firewall-cmd --reload14.3.解决问题按照以上步骤操作,应该能够解决 mysqld 执行时提示 “No such file or directory” 的问题。 最后发现自己下载的第一个32位软件 自己下错版本信息了 最后下载64位安装就成功了,再也没有提示错误了endl
-
Mysql数据库 @TOC1.范例: 针对一个电商项目创建项目的管理员用户mysql> create database eshop; Query OK, 1 row affected (0.00 sec) mysql> create user eshop@'10.0.0.%' identified by '123456'; Query OK, 0 rows affected (0.01 sec) mysql> grant all on eshop.* to eshop@'10.0.0.%'; Query OK, 0 rows affected (0.01 sec) ALTER USER 'eshop'@'10.0.0.%' IDENTIFIED WITH mysql_native_password BY '123456';2.mysqldump 备份工具2.1.mysqldump 常见通用选项::star::star::star::star::star::star:-u, --user=name User for login if not current user -p, --password[=name] Password to use when connecting to server -A, --all-databases #备份所有数据库,含create database -B, --databases db_name… #指定备份的数据库,包括create database语句 -E, --events: #备份相关的所有event scheduler -R, --routines: #备份所有存储过程和自定义函数 --triggers: #备份表相关触发器,默认启用,用--skip-triggers,不备份触发器 --default-character-set=utf8 #指定字符集 --master-data[=#]:#注意:MySQL8.0.26版以后,此选项变为--source-data #此选项须启用二进制日志 #1:所备份的数据之前加一条记录为CHANGE MASTER TO语句,非注释,不指定#,默认为1,适合于主从复制多机使用 #2:记录为被注释的#CHANGE MASTER TO语句,适合于单机使用,适用于备份还原 #此选项会自动关闭--lock-tables功能,自动打开-x | --lock-all-tables功能(除非开启--single-transaction) -F, --flush-logs #备份前滚动日志,锁定表完成后,执行flush logs命令,生成新的二进制日志文件, #配合-A 或 -B 选项时,会导致刷新多次数据库。 #建议在同一时刻执行转储和日志刷新,可通过和--single-transaction或-x,--master-data 一起使用实现, #此时只刷新一次二进制日志 --compact #去掉注释,适合调试,节约备份占用的空间,生产不使用 -d, --no-data #只备份表结构,不备份数据,即只备份create table -t, --no-create-info #只备份数据,不备份表结构,即不备份create table -n,--no-create-db #不备份create database,可被-A或-B覆盖 --flush-privileges #备份mysql或相关时需要使用 -f, --force #忽略SQL错误,继续执行 --hex-blob #使用十六进制符号转储二进制列,当有包括BINARY,VARBINARY,BLOB,BIT的数据类型的列时使用,避免乱码 -q, --quick #不缓存查询,直接输出,加快备份速度2.2.生产环境实战备份策略2.2.1.InnoDB建议备份策略:star::star::star::star::star::star:--master-data[=#]:#注意:MySQL8.0.26版以后,此选项变为--source-datamysqldump -uroot -p123456 -A -F -E -R --triggers --single-transaction --master-data=2 --flush-privileges --default-character-set=utf8 --hex-blob >${BACKUP}/fullbak_${BACKUP_TIME}.sql #新版8.0.26以上 mysqldump -uroot -p123456 -A -F -E -R --triggers --single-transaction --source-data=2 --flush-privileges --default-character-set=utf8 --hex-blob >${BACKUP}/fullbak_${BACKUP_TIME}.sql2.2.2.MyISAM建议备份策略:star::star::star::star::star::star:mysqldump -uroot -p123456 -A -F -E -R -x --master-data=1 --flush-privileges --triggers --default-character-set=utf8 --hex-blob >${BACKUP}/fullbak_${BACKUP_TIME}.sql2.2.3.实战案例:特定数据库的备份脚本vim mysql_backup.sh#!/bin/bash TIME=`date +%F_%H-%M-%S` DIR=/backup DB=hellodb PASS=123456 [ -d $DIR ] || mkdir $DIR mysqldump -uroot -p "$PASS" -F -E -R --triggers --single-transaction --master-data=2 --default-character-set=utf8 -q -B $DB | gzip >${DIR}/${DB}_${TIME}.sql.gz2.3.安装数据库脚本【在线离线下载版】#!/bin/bash #MySQL5.7 Download URL: #https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz #https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.37-linux-glibc2.12-x86_64.tar.gz #https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz #MySQL8.0 Download URL: #https://downloads.mysql.com/archives/get/p/23/file/mysql-8.0.28-linux-glibc2.12-x86_64.tar.xz #https://downloads.mysql.com/archives/get/p/23/file/mysql-8.0.39-linux-glibc2.12-x86_64.tar.xz . /etc/init.d/functions SRC_DIR=`pwd` #MYSQL='mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz' #URL='https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.44-linux-glibc2.12-x86_64.tar.gz' MYSQL='mysql-8.0.39-linux-glibc2.12-x86_64.tar.xz' URL='https://downloads.mysql.com/archives/get/p/23/file/mysql-8.0.39-linux-glibc2.12-x86_64.tar.xz' COLOR='echo -e \E[01;31m' END='\E[0m' #MYSQL_ROOT_PASSWORD=magedu MYSQL_ROOT_PASSWORD=123456 check (){ if [ $UID -ne 0 ]; then action "当前用户不是root,安装失败" false exit 1 fi cd $SRC_DIR if [ ! -e $MYSQL ];then $COLOR"缺少${MYSQL}文件"$END $COLOR"正在在线下载,请稍后......"$END rpm -q wget || yum -y install wget wget ${URL} elif [ -e /usr/local/mysql ];then action "数据库已存在,安装失败" false exit else return fi if [ ! -e $MYSQL ];then $COLOR"缺少${MYSQL}文件"$END $COLOR"未下载成功,请将相关软件放在${SRC_DIR}目录下"$END exit fi } install_mysql(){ $COLOR"开始安装./.."$END yum -y -q install libaio numactl-libs ncurses-compat-libs &>/dev/null cd $SRC_DIR tar xf $MYSQL -C /usr/local/ MYSQL_DIR=`echo $MYSQL| sed -nr 's/^(.*[0-9]).*/\1/p'` ln -s /usr/local/$MYSQL_DIR /usr/local/mysql chown -R root.root /usr/local/mysql/ id mysql &> /dev/null || { useradd -s /sbin/nologin -r mysql ; action "创建mysql用户"; } echo 'PATH=/usr/local/mysql/bin/:$PATH' > /etc/profile.d/mysql.sh . /etc/profile.d/mysql.sh ln -s /usr/local/mysql/bin/* /usr/bin/ cat > /etc/my.cnf <<-EOF [mysqld] server-id=1 log-bin datadir=/data/mysql socket=/data/mysql/mysql.sock log-error=/data/mysql/mysql.log pid-file=/data/mysql/mysql.pid character-set-server=utf8mb4 [client] user=root password=123456 socket=/data/mysql/mysql.sock default-character-set=utf8mb4 EOF [ -d /data ] || mkdir /data mysqld --initialize --user=mysql --datadir=/data/mysql cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld chkconfig --add mysqld chkconfig mysqld on service mysqld start [ $? -ne 0 ] && { $COLOR"数据库启动失败,退出!"$END;exit; } sleep 3 MYSQL_OLDPASSWORD=`awk '/A temporary password/{print $NF}' /data/mysql/mysql.log` mysqladmin -uroot -p$MYSQL_OLDPASSWORD password $MYSQL_ROOT_PASSWORD &>/dev/null action "数据库安装完成" } check install_mysql3.mysql备份和恢复3.1.二进制日志记录三种格式二进制日志记录三种格式基于"语句"记录:statement,记录语句,默认模式( MariaDB 10.2.3 版本以下 ),日志量较少基于"行"记录:row,记录数据,日志量较大,更加安全,建议使用的格式,MySQL8.0默认格式混合模式:mixed, 让系统自行判定该基于哪种方式进行,默认模式( MariaDB 10.2.4及版本以上)3.3.切换日志文件mysql> FLUSH LOGS;3.4.生成二进制日志binlog[root@Rocky8 ~]#mysqladmin flush-binary-log [root@Rocky8 ~]#mysqladmin flush-logs [root@Rocky8 ~]#mysql MariaDB [hellodb]> flush logs;生成二进制日志文件的情况restart mysqld 1G 满了 mysql -e 'flush logs' mysqladmin flush-logs mysqldump -F3.5.启用二进制日志(备份)#MySQL 8.0 默认使用ROW方式 #基于"行"记录:row,记录数据,日志量较大,更加安全,建议使用的格式,MySQL8.0默认格式 mysql> show variables like 'binlog_format'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | binlog_format | ROW | +---------------+-------+ 1 row in set (0.00 sec)mysql> select @@sql_log_bin; +---------------+ | @@sql_log_bin | +---------------+ | 1 | +---------------+ 1 row in set (0.00 sec) mysql> select @@log_bin; +-----------+ | @@log_bin | +-----------+ | 1 | +-----------+ 1 row in set (0.00 sec)3.6.实战案例:恢复误删除的表【案例】:warning:案例说明:每天2:30做完全备份,早上10:00误删除了表students,10:10才发现故障,现需要将数据库还原到10:10的状态,且恢复被删除的scores表3.6.1.安装Mysql,启用二进制日志,并导入测试文件# 安装mysql yum -y install mysql-server mysql # 检查是否启用二进制日志(备份) mysql> select @@sql_log_bin; mysql> select @@log_bin; mysql> show variables like 'binlog_format'; # 修改root密码 mysql> select user,host from mysql.user; mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'NewPassword'; # 导入测试文件 mysql <hellodb_innodb.sql3.6.2.检查二进制日志ll /var/lib/mysql3.6.3.备份所有数据库mkdir /backup mysqldump -uroot -p123456 -A --source-data=2 >/backup/all.sql3.6.4.删表---【模拟数据库破坏】:warning:mysql> use hellodb; mysql> drop tables scores;3.6.5.增加数据---【模拟数据库破坏】:warning:mysql> insert into teachers (name,age,gender)values('a',18,'M'),('b',20,'F');3.6.6.模拟数据库恢复【备份文件+二进制日志】head /backup/all.sql -n 303.6.7.检查二进制日志ll /var/lib/mysql3.6.8.导出二进制日志文件mysqlbinlog --start-position=21693 /var/lib/mysql/binlog.000001 >/backup/logbin.sql grep -ni drop /backup/logbin.sql #36行 #awk 'NR==36' /backup/logbin.sql #删除这行 sed -i.bak '/^DROP TABLE `scores`/d' /backup/logbin.sql sed -Ei.bak '/^DROP TABLE `scores`/s/^/#/' /backup/logbin.sql3.6.9.拷贝到测试机进行还原【测试机还原】:warning:测试机需要相同的mysql版本环境rsync -avz /backup/logbin.sql /backup/all.sql root@10.0.0.38:yum -y install mysql-server mysql -uroot # 临时关闭二进制日志 mysql> set sql_log_bin=0; Query OK, 0 rows affected (0.00 sec) mysql> source all.sql; mysql> source logbin.sql; # 临时开启二进制日志 mysql> set sql_log_bin=1; Query OK, 0 rows affected (0.00 sec)3.6.10.检查是否还原【success】3.6.11.导入生产环境进行恢复单表备份数据恢复 3.7.保留备份--模拟删除数据库yum -y install mysql-server # 备份数据 mysqldump -uroot -p123456 -A -F --single-transaction --source-data=2 >/backup/all.sql systemctl stop mysqld rm -rf /data/mysql/* systemctl start mysqld #数据库恢复 mysql -uroot </backup/all.sql #刷新权限 mysql> flush privileges;4.xtrabackup 备份工具XtraBackup:https://www.percona.com/downloads5.Mysql主从复制5.1.主从复制架构及原理:star::star::star::star::star::star:主从复制相关线程:主节点:dump Thread : 为每个Slave的I/O Thread启动一个dump线程,用于向其发送binary log events从节点:I/O Thread :向Master请求二进制日志事件,并保存于中继日志中SQL Thread : 从中继日志中读取日志事件,在本地完成重放主从复制的基本原理:主从复制基于二进制日志(Binary Log, binlog)和中继日志(Relay Log)来实现。主服务器(Master):记录所有对数据库进行更改的 SQL 语句(如 INSERT、UPDATE、DELETE 等)到二进制日志(binlog)中。将 binlog 发送给从服务器。从服务器(Slave):接收主服务器发送的 binlog,并将其写入中继日志(relay log)。从中继日志中读取 SQL 语句,并在从服务器上执行这些语句,从而保持与主服务器数据的一致性。5.2.实现主从复制配置【实验】【Mysql.8.0.36】:star::star:yum -y install mysql-serverreset slave all;#删除同步信息5.2.1.主节点配置5.2.1.1.启用二进制日志5.2.1.2.为当前节点设置一个全局惟一的ID号vim /etc/my.cnf [mysqld] server-id=8 log-bin=/data/mysql/logbin/mysql-bin# 存储二进制日志文件夹 mkdir -p /data/mysql/logbin/ chown -R mysql.mysql /data/mysql/ # 开机启动 systemctl enable --now mysqld5.2.1.3.查看从二进制日志的文件和位置开始进行复制mysql> show master status;5.2.1.4.创建有复制权限的用户账号# MySQL8.0 分成两步实现 # 创建账号 mysql> create user repluser@'10.0.0.%' identified by '123456'; # 授权 mysql> grant replication slave on *.* to repluser@'10.0.0.%';5.2.2.从节点配置5.2.2.1.启用二进制日志5.2.2.2.为当前节点设置一个全局惟一的ID号vim /etc/my.cnf [mysqld] server-id=18 #为当前节点设置一个全局惟的ID号 read_only #设置数据库只读,针对supper user无效 log-bin=/data/mysql/logbin/mysql-bin# 存储二进制日志文件夹 mkdir -p /data/mysql/logbin/ chown -R mysql.mysql /data/mysql/ # 开机启动 systemctl enable --now mysqld5.2.2.3.查看主从同步状态,设置从库读取主库的服务器配置mysql> help change master to mysql> show slave status; CHANGE MASTER TO MASTER_HOST='10.0.0.8', MASTER_USER='repluser', MASTER_PASSWORD='123456', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=157, MASTER_CONNECT_RETRY=2;主从复制命令参数说明: master_host : 主数据库的IP地址; master_port : 主数据库的运行端口; master_user : 在主数据库创建的用于同步数据的用户账号; master_password : 在主数据库创建的用于同步数据的用户密码; master_log_file : 指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数; master_log_pos : 指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数; master_connect_retry : 连接失败重试的时间间隔,单位为秒。5.2.2.4.开启线程,查看状态mysql> show processlist; mysql> start slave; mysql> show slave status\G;5.3.主从复制【模拟企业环境--备份】5.3.1.主节点【先整体备份数据库】vim /etc/my.cnf [mysqld] server-id=8 log-bin=/data/mysql/logbin/mysql-bin# 存储二进制日志文件夹 mkdir -p /data/mysql/logbin/ chown -R mysql.mysql /data/mysql/ # 开机启动 systemctl enable --now mysqldmysql <hellodb_innodb.sql # MySQL8.0 分成两步实现 # 创建账号 mysql> create user repluser@'10.0.0.%' identified by '123456'; # 授权 mysql> grant replication slave on *.* to repluser@'10.0.0.%'; mysql> show master status; # 数据库备份 mysqldump -uroot -A -F --single-transaction --source-data=1 >/data/full_back.sql #拷贝到从节点上 scp /data/full_back.sql 10.0.0.18:/data/5.3.2.从节点vim /etc/my.cnf [mysqld] server-id=18 read_only log-bin=/data/mysql/logbin/mysql-bin# 存储二进制日志文件夹 mkdir -p /data/mysql/logbin/ chown -R mysql.mysql /data/mysql/ # 开机启动 systemctl enable --now mysqld5.3.3.从节点还原数据库临时将二进制日志关闭,恢复数据后再开启可以将change master to放在修改文件里也可以直接进入mysql,先还原数据库,再change maseter CHANGE MASTER TO MASTER_HOST='10.0.0.8', MASTER_USER='repluser', MASTER_PASSWORD='123456', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=157, MASTER_CONNECT_RETRY=2;# 临时关闭二进制日志 mysql> set sql_log_bin=0; mysql> source /data/full_back.sql; # 检查工作 mysql> show slave status\G; # 开启线程 mysql> start slave; mysql> show processlist; mysql> show slave status\G; # 开启二进制日志 mysql> set sql_log_bin=1;5.4.下载mysql-server及依赖包到本地mkdir mysql-server-packages-8.0.36 cd mysql-server-packages-8.0.36 yum install yum-utils -y yumdownloader --resolve mysql-server # 安装 yum -y install *5.5.三台主机实现级联复制需要在中间的从服务器启用以下配置 ,实现中间slave节点能将master的二进制日志在本机进行数据库更新,并且也同时更新本机的二进制,从而实现级联复制 同前面#在10.0.0.8充当master #在10.0.0.18充当级联slave #在10.0.0.28充当slave18机器vim /etc/my.cnf [mysqld] server-id=18 read_only log-bin=/data/mysql/logbin/mysql-bin #级联复制中间节点的必选项,MySQL8.0此为默认值,可以不要人为添加,其它版本默认不开启 log_slave_updates mysqldump -uroot -A -F --single-transaction --source-data=1 >/data/all.sql scp /data/all.sql 10.0.0.28:28机器CHANGE MASTER TO MASTER_HOST='10.0.0.18', MASTER_USER='repluser', MASTER_PASSWORD='123456', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000004', MASTER_LOG_POS=157, MASTER_CONNECT_RETRY=2;mysql> set sql_log_bin=0; mysql> source all.sql; mysql> show slave status\G; mysql> start slave; mysql> show slave status\G; mysql> set sql_log_bin=1;5.6.主主复制【会发生冲突】:warning::warning::warning:在一主一从基础上机器修改都一样vim /etc/my.cnf [mysqld] server-id=18 #read_only log-bin=/data/mysql/logbin/mysql-bin #log_slave_updates8机器,需要在18机器查看下日志位置CHANGE MASTER TO MASTER_HOST='10.0.0.18', MASTER_USER='repluser', MASTER_PASSWORD='123456', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000005', MASTER_LOG_POS=465;18机器,查位置8机器测试添加记录是否同步mysql> insert into teachers (name,age,gender)values('Libai',20,'M'); mysql> insert into teachers (name,age,gender)values('王五',50,'F'); mysql> select * from teachers;5.7.实现半同步复制【主从复制基础上】【Rocky8】:one:主服务器安装插件8#主服务器配置: mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; #永久安装插件 mysql> UNINSTALL PLUGIN rpl_semi_sync_master ; #删除插件 mysql> SHOW GLOBAL VARIABLES LIKE '%semi%'; mysql> SHOW PLUGINS; #查看插件 mysql> SHOW GLOBAL STATUS LIKE '%semi%'; #查看有几个从节点,客户端:two:从服务器安装插件18#从服务器配置: mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; #永久安装插件 mysql> UNINSTALL PLUGIN rpl_semi_sync_slave ; #删除插件 mysql> SHOW GLOBAL VARIABLES LIKE '%semi%'; mysql> SHOW PLUGINS; #查看插件:three:主服务器8vim /etc/my.cnf [mysqld] server-id=8 log-bin=/data/mysql/logbin/mysql-bin rpl_semi_sync_master_enabled #修改此行,需要先安装semisync_master.so插件后,再重启,否则无法启动 rpl_semi_sync_master_timeout=3000 #设置3s内无法同步,也将返回成功信息给客户端 systemctl restart mysqld mysql> select @@rpl_semi_sync_master_enabled;:four:从服务器18vim /etc/my.cnf [mysqld] server-id=18 log-bin=/data/mysql/logbin/mysql-bin rpl_semi_sync_slave_enabled #修改此行,需要先安装semisync_slave.so插件后,再重启,否则无法启动 systemctl restart mysqld mysql> select @@rpl_semi_sync_slave_enabled;:five:从服务器28vim /etc/my.cnf [mysqld] server-id=28 log-bin=/data/mysql/logbin/mysql-binmkdir -p /data/mysql/logbin/ chown -R mysql.mysql /data/mysql/ systemctl start mysqld安装插件,更改配置,重启服务#从服务器配置: mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; #永久安装插件 mysql> UNINSTALL PLUGIN rpl_semi_sync_slave ; #删除插件 mysql> SHOW GLOBAL VARIABLES LIKE '%semi%'; mysql> SHOW PLUGINS; #查看插件vim /etc/my.cnf [mysqld] server-id=28 log-bin=/data/mysql/logbin/mysql-bin rpl_semi_sync_slave_enabled systemctl restart mysqld mysql> select @@rpl_semi_sync_slave_enabled;CHANGE MASTER TO MASTER_HOST='10.0.0.8', MASTER_USER='repluser', MASTER_PASSWORD='123456', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000007', MASTER_LOG_POS=157, MASTER_CONNECT_RETRY=2;6.复制的问题和解决方案:star::star::star::star::star:6.1.数据损坏或丢失Master:MHA + semisync replicationSlave: 重新复制6.2.不惟一的 server id解决方法: 重新复制6.3.复制延迟升级到MySQL5.7以上版本(5.7之前的版本,没有开GTID之前,主库可以并发事务,但是dump传输时是串行)利用GTID(MySQL5.6需要手动开启,MySQL5.7以上默认开启)支持并发传输binlog及并行多个SQL线程减少大事务,将大事务拆分成小事务减少锁sync_binlog=1 加快binlog更新时间,从而加快日志复制需要额外的监控工具的辅助多线程复制:对多个数据库复制一从多主:Mariadb10 版后支持6.4.MySQL 主从数据不一致6.4.1.造成主从不一致的原因主库binlog格式为Statement,同步到从库执行后可能造成主从不一致。主库执行更改前有执行set sql_log_bin=0,会使主库不记录binlog,从库也无法变更这部分数据。从节点未设置只读,误操作写入数据主库或从库意外宕机,宕机可能会造成binlog或者relaylog文件出现损坏,导致主从不一致主从实例版本不一致,特别是高版本是主,低版本为从的情况下,主数据库上面支持的功能,从数据库上面可能不支持该功能主从sql_mode 不一致MySQL自身bug导致6.4.2.主从不一致修复方法:one:将从库重新实现虽然这也是一种解决方法,但是这个方案恢复时间比较慢,而且有时候从库也是承担一部分的查询操作的,不能贸然重建。:two:使用percona-toolkit工具辅助PT工具包中包含pt-table-checksum和pt-table-sync两个工具,主要用于检测主从是否一致以及修复数据不一致情况。这种方案优点是修复速度快,不需要停止主从辅助,缺点是需要知识积累,需要时间去学习,去测试,特别是在生产环境,还是要小心使用关于使用方法,可以参考下面链接:https://www.cnblogs.com/feiren/p/7777218.html:three:手动重建不一致的表在从库发现某几张表与主库数据不一致,而这几张表数据量也比较大,手工比对数据不现实,并且重做整个库也比较慢,这个时候可以只重做这几张表来修复主从不一致这种方案缺点是在执行导入期间需要暂时停止从库复制,不过也是可以接受的:four:范例:A,B,C这三张表主从数据不一致1、从库停止Slave复制 mysql> stop slave; 2、在主库上dump这三张表,并记录下同步的binlog和POS点 mysqldump -uroot -pmagedu -q --single-transaction --master-data=2 testdb A B C >/backup/A_B_C.sql 3、查看A_B_C.sql文件,找出记录的binlog和POS点 head A_B_C.sql 例如:MASTERLOGFILE='mysql-bin.888888', MASTERLOGPOS=666666; #以下指令是为了保障其他表的数据不丢失,一直同步直到那个点结束,A,B,C表的数据在之前的备份已 经生成了一份快照,只需要导入进入,然后开启同步即可 4、把A_B_C.sql拷贝到Slave机器上,并做指向新位置 mysql> start slave until MASTERLOGFILE='mysql-bin.888888',MASTERLOGPOS=666666; 5、在Slave机器上导入A_B_C.sql mysql -uroot -pmagedu testdb mysql> set sql_log_bin=0; mysql> source /backup/A_B_C.sql mysql> set sql_log_bin=1; 6、导入完毕后,从库开启同步即可。 mysql> start slave;6.4.3.如何避免主从不一致主库binlog采用ROW格式主从实例数据库版本保持一致主库做好账号权限把控,不可以执行set sql_log_bin=0从库开启只读,不允许人为写入定期进行主从一致性检验7.实现MHA实战案例项目我在工作中设置了mysql主从,设置了半同步,设置了GTD,并且我又添加了MHA 环境:四台主机ip版本角色10.0.0.7Centos7MHA管理端10.0.0.8Rocky8MySQL8.0 Master10.0.0.18Rocky8MySQL8.0 Slave110.0.0.28Rocky8MySQL8.0 Slave27.1.在管理节点上安装两个包mha4mysql-manager和mha4mysql-node【manager】说明:mha4mysql-manager-0.58-0.el7.centos.noarch.rpm 只支持CentOS7上安装, 不支持在CentOS8安装,支持MySQL5.7和MySQL8.0 ,但和CentOS8版本上的Mariadb-10.3.17不兼容 mha4mysql-manager-0.56-0.el6.noarch.rpm 不支持CentOS 8,只支持CentOS7及以下版本两个安装包:mha4mysql-manager mha4mysql-node #下载 https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads https://github.com/yoshinorim/mha4mysql-node/releases/tag/v0.58 https://github.com/yoshinorim/mha4mysql-node/releases/tag/v0.58案例:yum -y install epel-release yum -y install mha4mysql-manager-0.58-0.el7.centos.noarch.rpm mha4mysql-node-0.58-0.el7.centos.noarch.rpmrpm -ql mha4mysql-manager7.2.在所有MySQL服务器上安装mha4mysql-node包此包支持CentOS 8,7,6yum -y install mha4mysql-node-0.58-0.el7.centos.noarch.rpm7.3.在所有节点实现基于 ssh-key 的免密登录#生成密钥对,并在当前主机完成C/S校验 [root@mha-manager ~]# ssh-keygen [root@mha-manager ~]# ssh-copy-id 127.0.0.1 [root@mha-manager ~]# ll .ssh #分发 [root@mha-manager ~]# rsync -av .ssh 10.0.0.8:/root/ [root@mha-manager ~]# rsync -av .ssh 10.0.0.18:/root/ [root@mha-manager ~]# rsync -av .ssh 10.0.0.28:/root/ #测试ssh连接 ......7.4.在 mha-manager 节点创建相关配置文件mkdir /etc/mastermha/ vim /etc/mastermha/app1.cnf [server default] user=mhauser #用于远程连接MySQL所有节点的用户,需要有管理员的权限 password=123456 manager_workdir=/data/mastermha/app1/ #目录会自动生成,无需手动创建 manager_log=/data/mastermha/app1/manager.log #当前集群的日志 remote_workdir=/data/mastermha/app1/ #mysql 节点mha 工作目录,会自动创建 ssh_user=root #用于实现远程ssh基于KEY的连接,访问二进制日志 repl_user=repluser #主从复制的用户信息 repl_password=123456 ping_interval=1 #健康性检查的时间间隔,manager节点对于master节点的心跳检测时间间隔 master_ip_failover_script=/usr/local/bin/master_ip_failover #切换VIP的perl脚本,不支持跨网络,也可用Keepalived实现 report_script=/usr/local/bin/sendmail.sh #当执行报警脚本 check_repl_delay=0 #默认值为1,表示如果slave中从库落后主库relay log超过100M,主库不会选择这个从库为新的master, #因为这个从库进行恢复需要很长的时间.通过设置参数check_repl_delay=0,mha触发主从切换时会忽略复制的延时, #对于设置candidate_master=1的从库非常有用,这样确保这个从库一定能成为最新的master master_binlog_dir=/data/mysql/logbin/ #指定二进制日志存放的目录,mha4mysql-manager-0.58必须指定,之前版本不需要指定 [server1] hostname=10.0.0.8 port=3306 candidate_master=1 [server2] hostname=10.0.0.18 port=3306 [server3] hostname=10.0.0.28 port=3306 candidate_master=1 #设置为优先候选master,即使不是集群中事件最新的slave,也会优先当master[server default] user=mhauser password=123456 manager_workdir=/data/mastermha/app1/ manager_log=/data/mastermha/app1/manager.log remote_workdir=/data/mastermha/app1/ ssh_user=root repl_user=repluser repl_password=123456 ping_interval=1 master_ip_failover_script=/usr/local/bin/master_ip_failover report_script=/usr/local/bin/sendmail.sh check_repl_delay=0 master_binlog_dir=/data/mysql/logbin/ [server1] hostname=10.0.0.8 port=3306 candidate_master=1 master_binlog_dir="/data/mysql/" [server2] hostname=10.0.0.18 port=3306 master_binlog_dir="/data/mysql/" [server3] hostname=10.0.0.28 port=3306 candidate_master=1 master_binlog_dir="/data/mysql/"说明: 主库宕机谁来接管新的master提升 slave 节点为 master 节点的策略 1. 所有从slave 节点日志都是一致的,默认会以配置文件的顺序去选择一个新主 2. 从节点日志不一致,自动选择数据量最接近于主库的从库充当新主,将其提升为master 节点。 3. 如果对于某节点设定了权重(candidate_master=1),权重节点会优先选择。但是此节点日志量落后主库超过100M日志的话,也不会被选择。 4. 可以配合check_repl_delay=0,关闭日志量的检查,强制选择候选节点7.5.发送邮件脚本:star::star::star::star::star:# 告警消息脚本 [root@mha-manager ~]# cat /usr/local/bin/sendmail.sh #!/bin/bash echo "MHA is failover!" | mail -s "MHA Warning" 649352141@qq.com [root@mha-manager ~]# chmod +x /usr/local/bin/sendmail.sh # 安装邮件服务 [root@mha-manager ~]# yum install mailx postfix # 邮件服务配置 [root@mha-manager ~]# vim /etc/mail.rc # 加在最下面 #发件箱 set from="2636775731@qq.com" # 配置的第三方smtp服务器的地址及端口 set smtp=smtp://smtp.qq.com:587 #发件人 set smtp-auth-user="2636775731@qq.com" #授权码 set smtp-auth-password=ttnvcrlfgywididb # 认证方式 set smtp-auth=login #开启ssl set ssl-verify=ignore set smtp-use-starttls=yes #证书目录,下方为centos系统证书默认位置,也自行生成证书并指定 set nss-config-dir=/etc/pki/nssdb --说明 from:对方收到邮件时显示的发件人 smtp:指定第三方发邮件的smtp服务器地址,云服务器必须使用465端口默认25端口被禁用 set smtp-auth-user:第三方发邮件的用户名 set smtp-auth-password: 邮箱的授权码注意不是密码 #echo "测试邮件" | mail -s "发送成功" 2636775731@qq.com &>/dev/null # 重新启动postfix [root@mha-manager ~]# systemctl restart postfix.service # 测试告警邮件 [root@mha-manager ~]# sendmail.sh[root@mha-manager ~]# vim /usr/local/bin/master_ip_failover #!/usr/bin/env perl # Copyright (C) 2011 DeNA Co.,Ltd. # # This program is free software; you can redistribute it and/or modify # it under the terms of the GNU General Public License as published by # the Free Software Foundation; either version 2 of the License, or # (at your option) any later version. # # This program is distributed in the hope that it will be useful, # but WITHOUT ANY WARRANTY; without even the implied warranty of # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the # GNU General Public License for more details. # # You should have received a copy of the GNU General Public License # along with this program; if not, write to the Free Software # Foundation, Inc., # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA ## Note: This is a sample script and is not complete. Modify the script based on your environment. use strict; use warnings FATAL => 'all'; use Getopt::Long; use MHA::DBHelper; my ( $command, $ssh_user, $orig_master_host, $orig_master_ip, $orig_master_port, $new_master_host, $new_master_ip, $new_master_port, $new_master_user, $new_master_password ); # 修改内容 my $vip = '10.0.0.100/24'; #virtually IP,此IP会在不同的MySQL节点漂移 my $key = "1"; my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; #在网卡上添加IP,确保每台 MySQL 节点网卡名一样 my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down"; GetOptions( 'command=s' => \$command, 'ssh_user=s' => \$ssh_user, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port, 'new_master_user=s' => \$new_master_user, 'new_master_password=s' => \$new_master_password, ); exit &main(); sub main { if ( $command eq "stop" || $command eq "stopssh" ) { # $orig_master_host, $orig_master_ip, $orig_master_port are passed. # If you manage master ip address at global catalog database, # invalidate orig_master_ip here. my $exit_code = 1; eval { # updating global catalog, etc $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "start" ) { # all arguments are passed. # If you manage master ip address at global catalog database, # activate new_master_ip here. # You can also grant write access (create user, set read_only=0, etc) here. my $exit_code = 10; eval { print "Enabling the VIP - $vip on the new master - $new_master_host \n"; &start_vip(); &stop_vip(); $exit_code = 0; }; if ($@) { warn $@; exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { print "Checking the Status of the script.. OK \n"; `ssh $ssh_user\@$orig_master_host \" $ssh_start_vip \"`; exit 0; } else { &usage(); exit 1; } } sub start_vip() { `ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`; } # A simple system call that disable the VIP on the old_master sub stop_vip() { `ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`; } sub usage { print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n"; }# 加上执行权限 chmod +x /usr/local/bin/master_ip_failover7.6.实现Master# 在 master 节点配置 VIP,此IP会在不同 MySQL 节点上漂移 ifconfig eth0:1 10.0.0.100/24 yum -y install mysql-server vim /etc/my.cnf [mysqld] server-id=8 log-bin=/data/mysql/mysql-bin mkdir -p /data/mysql/ chown -R mysql.mysql /data/mysql/ systemctl restart mysqld[root@master ~]#mysql mysql> show master logs; # 如果是MySQL8.0执行下面操操作 #创建主从同步账号并授权 mysql> create user repluser@'10.0.0.%' identified by '123456'; mysql> grant replication slave on *.* to repluser@'10.0.0.%'; #创建 mha-manager 使用的账号并授权 mysql> create user mhauser@'10.0.0.%' identified by '123456'; mysql> grant all on *.* to mhauser@'10.0.0.%'; # 如果是MySQL8.0以前版本执行下面操操作 mysql> grant replication slave on *.* to repluser@'10.0.0.%' identified by '123456'; mysql> grant all on *.* to mhauser@'10.0.0.%' identified by '123456';7.7.实现slave1yum -y install mysql-server vim /etc/my.cnf [mysqld] server-id=18 read-only log-bin=/data/mysql/mysql-bin mkdir -p /data/mysql/ chown -R mysql.mysql /data/mysql/ systemctl restart mysqld[root@slave1 ~]#mysql mysql> CHANGE MASTER TO MASTER_HOST='10.0.0.8', MASTER_USER='repluser', MASTER_PASSWORD='123456', MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=157; mysql> start slave; mysql> show slave status\G;# 重置slave mysql> stop slave; mysql> reset slave all;7.8.实现slave2yum -y install mysql-server vim /etc/my.cnf [mysqld] server-id=28 #不同节点此值各不相同 read-only log-bin=/data/mysql/mysql-bin mkdir -p /data/mysql/ chown -R mysql.mysql /data/mysql/ systemctl restart mysqld[root@slave1 ~]#mysql mysql> CHANGE MASTER TO MASTER_HOST='10.0.0.8', MASTER_USER='repluser', MASTER_PASSWORD='123456', MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=157; mysql> start slave; mysql> show slave status\G;# 重置slave mysql> stop slave; mysql> reset slave all;7.9.检查MHA的环境#检查环境 #配置和 SSH 连接检查 vim /etc/mastermha/app1.cnf #主从复制检查,会在mysql节点自动创建 remote_workdir=/data/mastermha/app1/ masterha_check_ssh --conf=/etc/mastermha/app1.cnf masterha_check_repl --conf=/etc/mastermha/app1.cnf #查看当前mysql 集群状态 masterha_check_status --conf=/etc/mastermha/app1.cnf7.10.启动MHA#开启MHA,默认是前台运行,生产环境一般为后台执行,并且与终端分离 nohup masterha_manager --conf=/etc/mastermha/app1.cnf --remove_dead_master_conf --ignore_last_failover &> /dev/null #测试环境: #masterha_manager --conf=/etc/mastermha/app1.cnf --remove_dead_master_conf --ignore_last_failover #如果想停止后台执行的MHA,可以执行下面命令 masterha_stop --conf=/etc/mastermha/app1.cnf Stopped app1 successfully. #查看状态 masterha_check_status --conf=/etc/mastermha/app1.cnf #查看生成的文件 tree /data/mastermha/app1/ #查看日志 cat /data/mastermha/app1/manager.log#开启 master 节点通用日志 mysql> set global general_log=1; Query OK, 0 rows affected (0.01 sec)tail -f /var/lib/mysql/Rocky8.log7.11.排错日志tail /data/mastermha/app1/manager.log7.12.模拟故障#模拟故障 [root@master ~]#systemctl stop mysqld #当 master down机后,mha管理程序自动退出 [root@mha-manager ~]#masterha_manager --conf=/etc/mastermha/app1.cnf[root@mha-manager ~]#cat /data/mastermha/app1/manager.log [root@mha-manager ~]#masterha_check_status --conf=/etc/mastermha/app1.cnf #验证VIP漂移至新的Master上 [root@slave1 ~]#ip a #自动修改manager节点上的配置文件,将master剔除 [root@mha-manager ~]#cat /etc/mastermha/app1.cnf [server2] candidate_master=1 hostname=10.0.0.18 master_binlog_dir="/data/mysql/" port=3306 [server3] hostname=10.0.0.28 master_binlog_dir="/data/mysql/" port=3306注意: 如果出错,需要删除下面文件再执行MHA[root@mha-manager ~]#rm -f /data/mastermha/app1/app1.failover.error7.13.修复主从修复故障的主库,保证数据同步 修复主从,手工新故障库加入新的主,设为为从库 修复manager的配置文件 清理相关目录 检查ssh互信和replication的复制是否成功 检查VIP,如果有问题,重新配置VIP 重新运行MHA,查询MHA状态,确保运行正常7.14.如果再次运行MHA,需要先删除下面文件MHA只能漂移一次,如果多次使用必须删除以下文件,要不MHA不可重用[root@mha-manager ~]#rm -rf /data/mastermha/app1/ # mha_master自己的工作路径 [root@mha-manager ~]#rm -rf /data/mastermha/app1/manager.log #m ha_master自己的日志文件 [root@master ~]#rm -rf /data/mastermha/app1/ # 每个远程主机即三个节点的的工作目录endl